原帖由 lepton 于 2008-11-30 16:25 发表
测试用的是intel 的linpack 9.1,属于MKL。
可能没有对nehalem特别优化,但对intel处理器是高度优化的,比如对sse的优化。
所以,恐怕很难说这测试偏向AMD。
原帖由 lepton 于 2008-11-30 16:25 发表
测试用的是intel 的linpack 9.1,属于MKL。
可能没有对nehalem特别优化,但对intel处理器是高度优化的,比如对sse的优化。
所以,恐怕很难说这测试偏向AMD。
原帖由 the_god_of_pig 于 2008-11-30 16:57 发表
Linpack有什么用,又不能吃{lol:]
原帖由 L2S 于 2008-11-30 17:07 发表
I U领先的项目哪个能吃?你吃个我看看{mellow:]
原帖由 lepton 于 2008-11-30 17:40 发表
楼上你真是个无厘头。
请回到一楼看标题。
原帖由 rtyou 于 2008-11-30 17:59 发表
上海终于找到一个可以和i7比较的项目?
恭喜AMD了。{closedeyes:]
原帖由 tomsmith123 于 2008-12-3 13:16 发表
Linpack 还是非常标志性的指标。HT OFF 性能更高,在我的试验中也重复出现了,我用ICC 最大优化,仍然不会改变这个结果,其实很容易解释,对于密集计算应用,ALU 本身不是瓶颈,而是从RAM 到ALU 的通路瓶颈。
原帖由 itany 于 2008-12-3 14:05 发表
Intel应该拉L1缓存的位宽了
现在不拉,Sandy肯定要拉了
原帖由 tomsmith123 于 2008-12-3 14:13 发表
和L1 关系不大。。。
这是冯氏计算机的癌症之一。
原帖由 itany 于 2008-12-3 14:37 发表
关键是阁下怎么解释超线程的情况下i7的性能下降呢?
原帖由 itany 于 2008-12-3 14:37 发表
关键是阁下怎么解释超线程的情况下i7的性能下降呢?
原帖由 tomsmith123 于 2008-12-3 15:19 发表
HT 开启后,逻辑核心多了,OS 调度是根据负载均衡原则调度的,由于事实上只有一套执行机制,在非ALU 瓶颈的情况下,两个逻辑核心在切换同一套执行机构使用,增加了额外的消耗。
另一方面,两个逻辑核心对CACHE ...
原帖由 itany 于 2008-12-3 17:17 发表
i7的超线程可不是两个逻辑核心在同一个执行机构上切换,而是两个逻辑核心并发的
我觉得主要还是执行路径的宽度上存在瓶颈,比如L1到取指缓冲队列的宽度,还有L1的大小。毕竟L1I在HT的情况下是平分给两个线程的
原帖由 tomsmith123 于 2008-12-3 18:03 发表
HT 是共享L1的。L1 的宽度成本很高,相当于整个内部总线的宽度,代价太高了。
SMT 或者HT 的意义在于,逻辑上两个线程的切换速度非常快,可以极大改善响应时效,对于密集计算,内存瓶颈的情况下,只能增加处理的负 ...
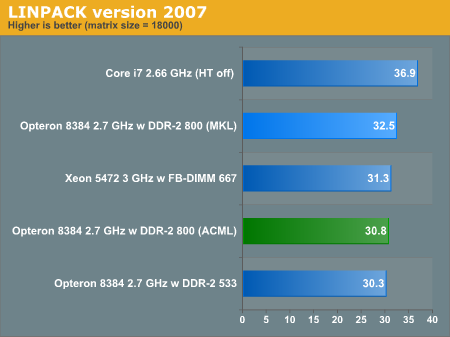
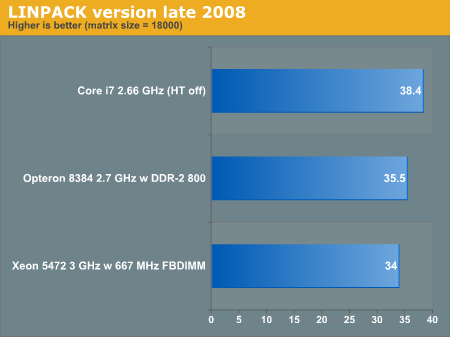
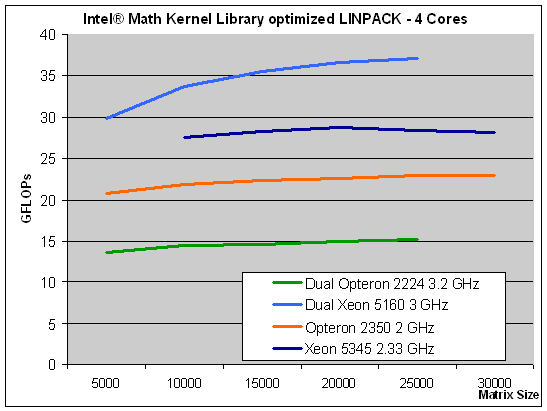
原帖由 lepton 于 2008-11-30 16:18 发表
上海的性能达到同频i7的87%(这个数字已经考虑2.7G与2.66G的频率差异),
感觉上海将K8核心潜能已经挖掘到了极限。
http://images.anandtech.com/graphs/amdshanghai_112208120910/17839.png
原文连接:http:// ...
原帖由 tomsmith123 于 2008-12-3 13:16 发表
Linpack 还是非常标志性的指标。HT OFF 性能更高,在我的试验中也重复出现了,我用ICC 最大优化,仍然不会改变这个结果,其实很容易解释,对于密集计算应用,ALU 本身不是瓶颈,而是从RAM 到ALU 的通路瓶颈。
原帖由 lepton 于 2008-12-8 16:53 发表
建议你做个测试,纵向、横向比较blas家族。
纵向:比较同频率core2,penryn,i7, 出于公平和使用,都评测物理4核心(包括2路双核,胶水4核,原生4核)。
横向:同一硬件平台比较blas,MKL,atlas,gotoblas。
不过 ...
原帖由 Edison 于 2008-12-8 11:37 发表
以前在 Cygwin 下比对过,差别很大,具体的数值忘记了,不过那是 1.02 时代的了。

| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
