不是很明白,只是感觉ATI架构有点模块化的意思。
jpfzyj 发表于 2010-3-13 19:38
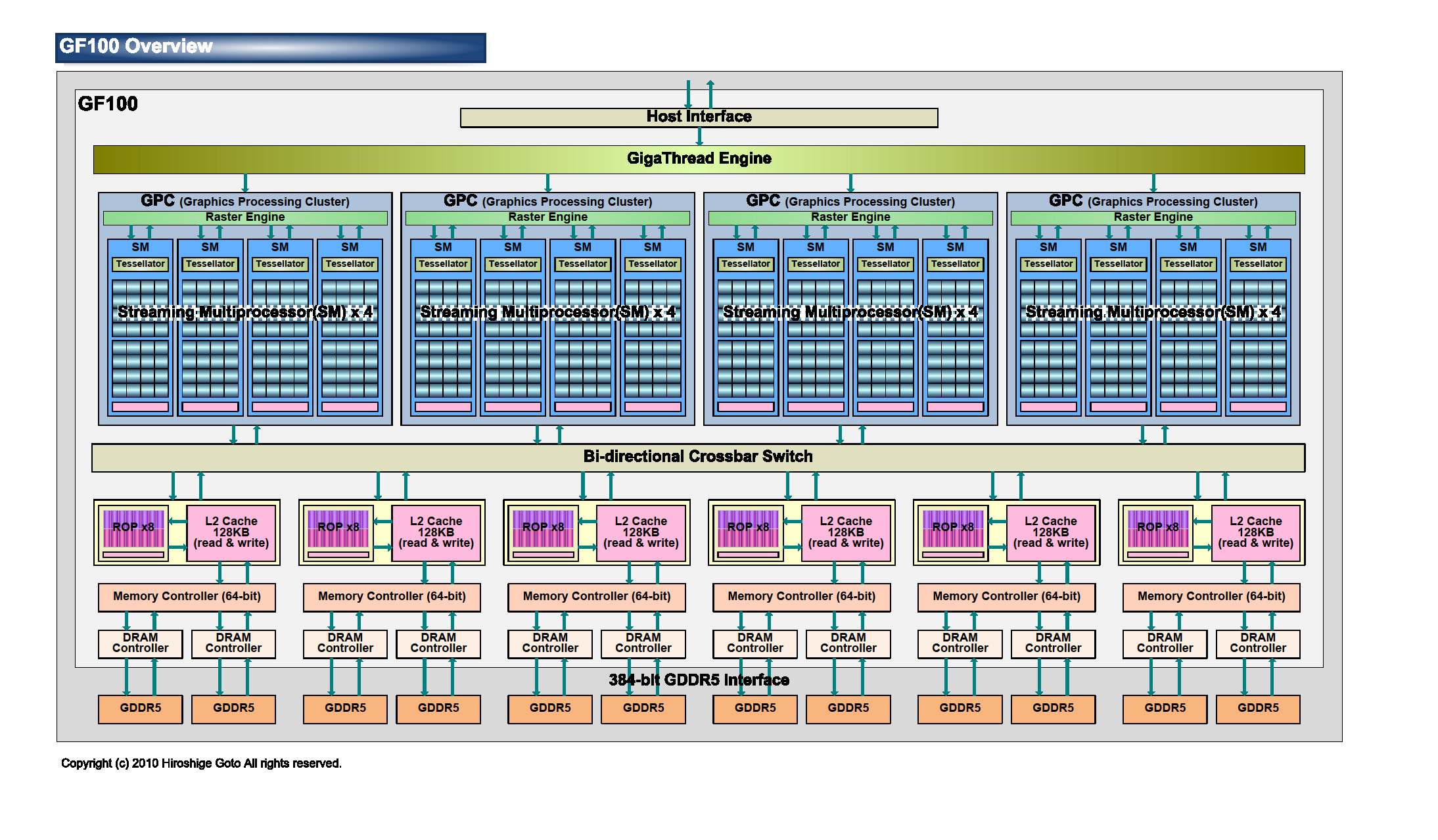


 学习了~
学习了~不是很明白,只是感觉ATI架构有点模块化的意思。
jpfzyj 发表于 2010-3-13 19:38
GPU 的设计本来就是高度模块化的,例如 TMU、shader、ROP 等等,都是在仿真器上进行了大量的测试后才经 ...
Edison 发表于 2010-3-13 23:38
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
