还没推出的东西 你测试过了?
直流电 发表于 2010-8-24 18:26

还没推出的东西 你测试过了?
直流电 发表于 2010-8-24 18:26
这2幅架构图太扯淡了,phenom 2哪来的2*128 fmac,bd也不是64k L1D。
hammerking 发表于 2010-8-24 18:54

两个128位fmac......k10啥时候这么牛了
spinup 发表于 2010-8-24 19:06
这2幅架构图太扯淡了,phenom 2哪来的2*128 fmac,bd也不是64k L1D。
hammerking 发表于 2010-8-24 18:54
论坛里面的高人真多,不去研发处理器太可惜了。
aidianzi 发表于 2010-8-24 19:18
现在太好玩了,Nehalem出来后,AMD的U对Intel出现了“插座门”惨剧,这次在桌面上除了“插座门”外,可能还 ...
AMD11 发表于 2010-8-24 18:07
AMD插座门是什么东西????
我只听过INTEL的插座门 真没听过AMD的
scowl 发表于 2010-8-25 00:18
关于推土机,可以不可以这么理解:单核性能小幅下降但是晶体管数大幅减少,准备和Intel玩“人海战术”靠数量 ...
xmasjacky 发表于 2010-8-25 00:48
我只想知道:
1,在晶体管数量大致相当的情况下,同频下推土机能推平沙桥么?在推土机 1模块 vs p2 1核心的 ...
westlee 发表于 2010-8-24 22:49
你看的是小core,
但一个模块有2独立core共享1FP+2*128fmac,这样一个模块过去叫一个“核心”。
take 发表于 2010-8-25 02:22

你看的是小core,
但一个模块有2独立core共享1FP+2*128fmac,这样一个模块过去叫一个“核心”。
take 发表于 2010-8-25 02:22
你看的是小core,
但一个模块有2独立core共享1FP+2*128fmac,这样一个模块过去叫一个“核心”。
take 发表于 2010-8-25 02:22
如果这样看的话,就不是小core了,而是一个超级大的core,AMD的预测分支和调度技术相对Intel而言相当 ...
AMD11 发表于 2010-8-25 08:29
45nmk10.5大约15平方毫米,对比nehalem大约25平方毫米。
已公布的llano中k10.5面积是不到10平方毫米,we ...
spinup 发表于 2010-8-25 10:12
预取与分支预测完全重做,相当激进。。
hammerking 发表于 2010-8-25 10:36
45nmk10.5大约15平方毫米,对比nehalem大约25平方毫米。
已公布的llano中k10.5面积是不到10平方毫米,we ...
spinup 发表于 2010-8-25 10:12
一个核心差不多就是10平方毫米到20的样子,差不了多少。
对于180到280平方毫米的处理器,差20平方并不 ...
itany 发表于 2010-8-25 01:49
、分支和预读的算法,当然现在不会具体公布,但是这篇文章给出了大体机制,完全翻新:
2alu 与 2agu并 ...
hammerking 发表于 2010-8-25 11:29
、分支和预读的算法,当然现在不会具体公布,但是这篇文章给出了大体机制,完全翻新:
2alu 与 2agu并 ...
hammerking 发表于 2010-8-25 11:29
5平方毫米对于整个芯片来说影响并不大,Intel通过L3密度就可以找回来的
Llano的10-面积是不包含L2缓存 ...
itany 发表于 2010-8-25 11:11
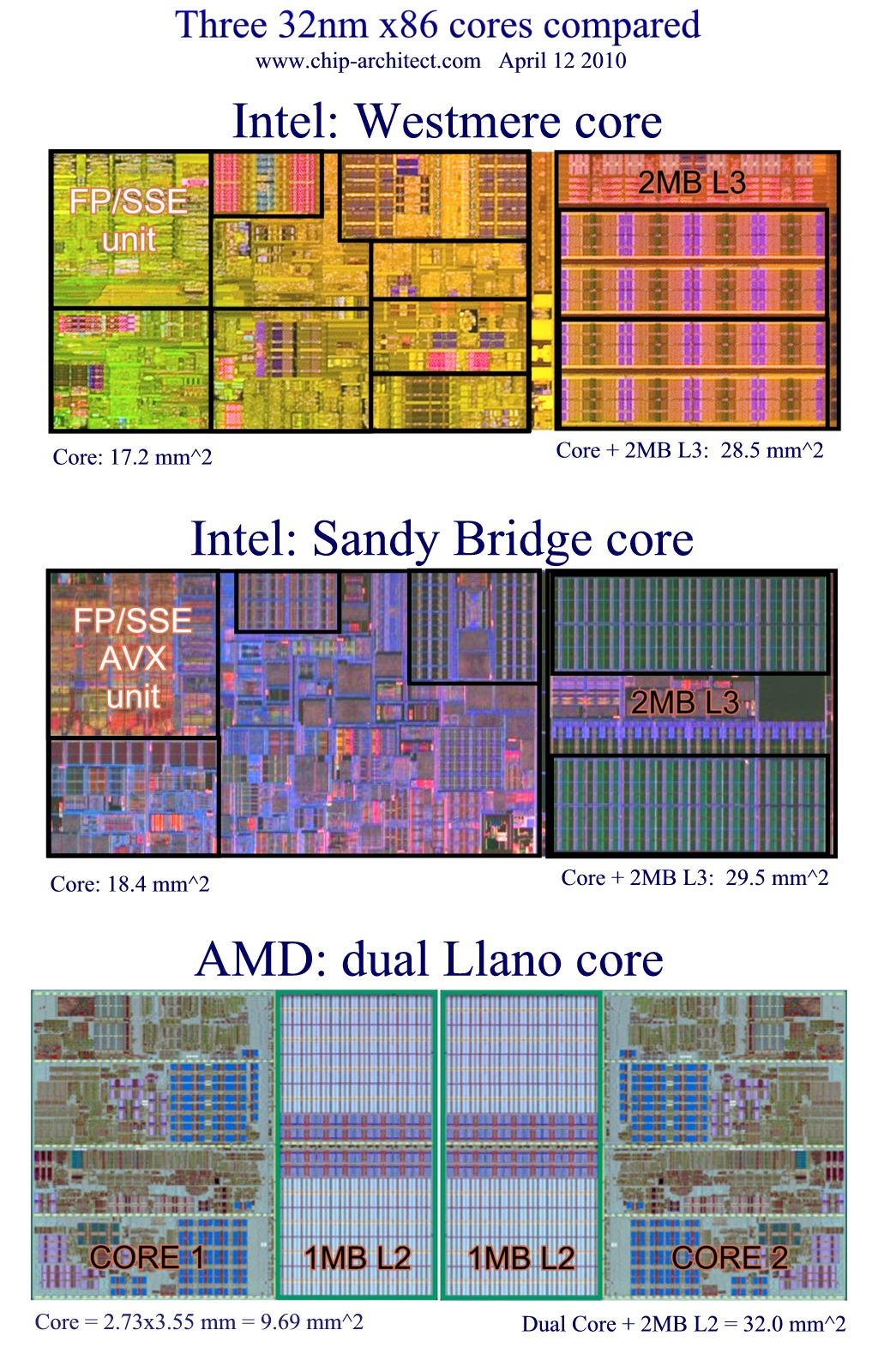
8模组的浮点资源与k10.5 16核相当了,所以用在hpc上还是会略有进步的。只是没有k8x2到k10那样夸张了。
spinup 发表于 2010-8-25 14:23
8模组的浮点资源与k10.5 16核相当了,所以用在hpc上还是会略有进步的。只是没有k8x2到k10那样夸张了。
spinup 发表于 2010-8-25 14:23
k8x2到k10那样夸张???
没理解
4479237 发表于 2010-8-25 14:55
K8的fpu是一个64位乘一个64位加。
K10对于sse来说是一个128位乘一个128位加。(不过对于x87仍然是一乘 ...
spinup 发表于 2010-8-25 15:05
8模组的浮点资源与k10.5 16核相当了,所以用在hpc上还是会略有进步的。只是没有k8x2到k10那样夸张了。
spinup 发表于 2010-8-25 14:23
K8的fpu是一个64位乘一个64位加。
K10对于sse来说是一个128位乘一个128位加。(不过对于x87仍然是一乘 ...
spinup 发表于 2010-8-25 15:05
2个128位加乘能比一个128位乘一个128位加强多少?
acqwer 发表于 2010-8-25 15:40
westmere的L2占面积相当小,从照片上看不到整个核心的1/9。也就是说除去L2,westmere将是15平方毫米左右 ...
fpu一直都有自己的load/store单元,---k7开始就是3个浮点单元,两个运算,一个misc(其实就是ld/st)。因为fpu的数据读写与整型部分差别非常大而对延迟很不敏感。注意netburst,所有型号的fpu数据都是只通过L2的,bd也这么做完全顺理成章。
spinup 发表于 2010-8-25 12:25
理论值是加倍。
其实应该比较的是一个128位加乘融合和一个128位乘并一个128位加。
理论上有折扣---加乘单元可能只提供一个端口,换句话说不能同时跑分立的一个加一个乘。
不过也有加成---融合的加乘运算实际比1乘后再1加要快不少。
不过折扣的情况其实挺罕见,但是软件编得好的话加成的情况倒是普遍的。 所以现在普遍使用FMACspinup 发表于 2010-8-25 16:28
理论值的确加倍,但是那是理想情况,运行linkpack肯定很好看。但是发射宽度极度缩小,一个模块(两 ...
AMD11 发表于 2010-8-25 18:00
我倒觉得推土机对程序的需求只是从指令级并行向线程级并行转变,单核的乱序性能还是在强化的
CC9K 发表于 2010-8-25 18:19
我认为你的提法欠妥或相矛盾,乱序是指令级,如果乱序加强,指令并行要加强。线程并行更注重顺序结构,用线程去并行处理“小的顺序事务”收益最大,尤其是将分支事务变成两个甚至多个线程去处理时,这样的收益巨大。
AMD11 发表于 2010-8-25 19:15

fpu一直都有自己的load/store单元,---k7开始就是3个浮点单元,两个运算,一个misc(其实就是ld/st)。因为fpu的数据读写与整型部分差别非常大而对延迟很不敏感。注意netburst,所有型号的fpu数据都是只通过L2的,bd也这么做完全顺理成章。
spinup 发表于 2010-8-25 12:25
人家是一个模块算成一个核心,lz非要将其拆成一半再和intel 比,那别玩了,那你想怎么比就怎么比。
tmz 发表于 2010-8-25 19:22
4模块 bd是与4核 sb比的,很明了嘛。在服务器端,8核sb有8模块16核 interlagos对上。
hammerking 发表于 2010-8-25 19:28
楼主的预测技术AMD拍马难追,不去做CPU而跑去产奶,真可惜了。
tanlwowo 发表于 2010-8-25 19:35
理论值的确加倍,但是那是理想情况,运行linkpack肯定很好看。但是发射宽度极度缩小,一个模块(两 ...
AMD11 发表于 2010-8-25 18:00
认为bd核心的整数性能比k10低,那有2个前提,一是bd的整数单元就是在k10的基础上消去1/3,二是k10的3个alu利用率很高。
而实际上bd的2alu和2agu是独立的,各自拥有完整管线,利用率更高,再结合改进相当大的预取,分支预测、宏融合以及需要重新设计的译码单元,bd核心的整数ipc肯定比k10要高。amd在总结里把单线程性能作为显著提升的要点之一提出来,应当是ipc提高与更先进的turbo模式共同作用的结果。
hammerking 发表于 2010-8-25 19:42
x86的指令发射宽度还是变大了的 3->4。在跑单线程任务时时怎么看也算是大水管进。
AMD应该是把宝押在以后应用程序大都是多线程并行化,大方向还是没错的。目前处理器单线程性能的提高到了怠涨期,即便对intel来说也是如此。
ifu 发表于 2010-8-25 19:50
我说的是core,不是modul,平均下来,一个core的发射宽度只有2,却有4个管线。呵呵,真可以将管线做缓存 ...
AMD11 发表于 2010-8-25 19:56
做单线程时,四发射肯定是为一个core服务,同样2*128fmac也可以被一个core占用。
以你的这个思路,你还是以bd的一个core对比sb的一个core,但假若4模块8核心bd真的能匹敌8核心sb,那intel要哭死了。
hammerking 发表于 2010-8-25 20:04
跑单线程程序时这当然不能按平均来算,它可以独占这实实在在的4发射x86。
ifu 发表于 2010-8-25 20:13
唉,太理想了,现在的操作系统还能做到如此纯粹吗?同一时刻只有一个进程/线程运行?我怎么看得像是没有 ...
AMD11 发表于 2010-8-25 21:06
回复 AMD11
莫非上帝拉出了楼主,让你有了非人的预测能力,靠文字图片就是预测?
你娃有水平就去做CPU啦,光说不做是棒槌,只会臆测就不允许其他说咯嘛?
tanlwowo 发表于 2010-8-25 21:10
你不是标题抱怨的单线程性能么?又改担忧多线程了?呵呵
ifu 发表于 2010-8-25 21:14
呵呵,是这样的:在现在的操作系统下,任何普及的桌面系统或比较可见的server(比如4路及以下),都不可能 ...
AMD11 发表于 2010-8-25 21:22

如果这个图不是AMD忽悠的话,按核心而论,L1缩水,AGU、ALU缩水,本人**一次,单线程基本没什么提高,甚至不如K10.5,浮点彻底废掉。看来以前的预测还是有效地,AMD想将浮点放在异构上。
另外,按照Bulldozer的架构方式,可能会衍生出一个顺序架构的东西。
以上仅是个人理解,有错误实属难免,不过个人很有信心,等待实物实测证实。, ...
AMD11 发表于 2010-8-24 17:52
K8的fpu是一个64位乘一个64位加。
K10对于sse来说是一个128位乘一个128位加。(不过对于x87仍然是一乘 ...
spinup 发表于 2010-8-25 15:05
又不是只有一个模块,多个模块的话单线程还是有机会独占一个核的
AlcatrazX 发表于 2010-8-25 23:33

如果用小“core”的观点看,发射宽度极度缩小,执行资源虽然也缩水了,可整数资源还是过剩,但是L1的缩小就变得不可理喻,一下子变到了 16KBD/core,相比K10.5的64KBD/core而言差了4倍。难道AMD自信自己的L2上能与Intel比吗?Intel的L2可达到 6~7周期,而且是独享的,并且L1D可是32KB。
根据这个图,可以预测,针对Bulldozer优化程序主要是那些具有良好顺序执行的非浮点密集的程序,这样才能最大地发挥Bulldozer的能力。可惜,服务器上面向事务的程序并不是很符合这个要求,除非优化再优化。但是AMD自身连编译器都做不了,在业界的能力和影响很小。因此,不难推测,Bulldozer的综合能力提高有限,同频下,以模块对K10.5核心,4对4,多线程也就15%~25%的提升,单线程就算了,不说也罢。
AMD11 发表于 2010-8-25 08:29
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
