itany 发表于 2010-11-13 17:53
楼主,你光看到前端宽度从3变成4,没看到是从单个核心专用变成两个核心共用么?
 等高手言论 膜拜A神
等高手言论 膜拜A神

itany 发表于 2010-11-13 17:53
楼主,你光看到前端宽度从3变成4,没看到是从单个核心专用变成两个核心共用么?
nom8393 发表于 2010-11-13 18:22
又没有测试结果,难道性能要靠YY么?
深谷白云 发表于 2010-11-13 20:07
怎么我看到的是integer issues per cycle是4?
itany 发表于 2010-11-13 21:04
说的是一个模组,两个核心
深谷白云 发表于 2010-11-13 21:11
那是256-bit AVX吧?
itany 发表于 2010-11-13 21:16
神马256bit AVX,Bulldozer有256bit运算单元吗
深谷白云 发表于 2010-11-13 21:21
这个我懒得跟你争论了,既然是看着图片说那就以图片为依据吧
xf-108 发表于 2010-11-13 21:29
两个128bit加一起不等于256bit……
按照AMD官方说法,那应该叫胶水。
深谷白云 发表于 2010-11-13 21:33
这图片是fans自己做的?不算官方的?
xf-108 发表于 2010-11-13 19:04
单模块四发射,杯具啊。
继续一模块打一核心吧,不要被反秒了。
xf-108 发表于 2010-11-13 21:35
PPT专业户说的很清楚了啊,两个128bit加起来总共256bit,按照农企胶水定律,这就是胶水啊。
至于胶水算不 ...
frankincense 发表于 2010-11-13 21:38
实际上就变成模块VS核心(Intel),核心(AMD)VS线程
xf-108 发表于 2010-11-13 21:41
执行资源上一个模块还是有优势的8:6。发射数打平4:4。
frankincense 发表于 2010-11-13 22:36
单论执行单元AMD从来都没落后过只是效率很成问题
深谷白云 发表于 2010-11-13 21:40
也就是这张图片是fans做的所以做不得准?所以上面写的256-bit AVX不是AMD的说法?

 很明显avx256指令这时候要拆解成两条128位微操作,一条通过浮点单元执行,另一条通过整型单元执行。也就是说早期的avx256应该是很弱的,否则整型单元与浮点单元的延迟很可能差距很大,不能匹配。
很明显avx256指令这时候要拆解成两条128位微操作,一条通过浮点单元执行,另一条通过整型单元执行。也就是说早期的avx256应该是很弱的,否则整型单元与浮点单元的延迟很可能差距很大,不能匹配。ekphone 发表于 2010-11-14 07:12
回复 深谷白云 的帖子
天使长居然有闲心和这些民用技术高人们扯了,这又不是雷达航电论坛
spinup 发表于 2010-11-14 10:28
snb和bd其实都爆了不少了。双方其实都有一些匪夷所思的设计。




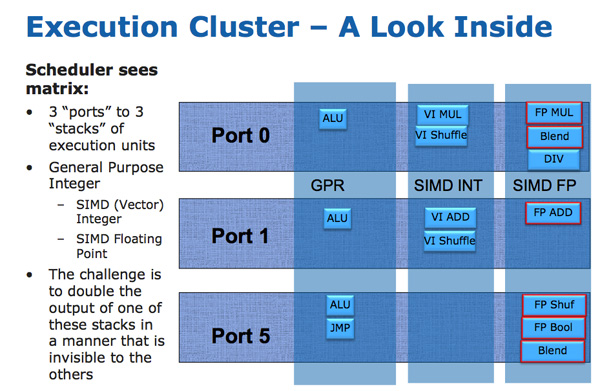
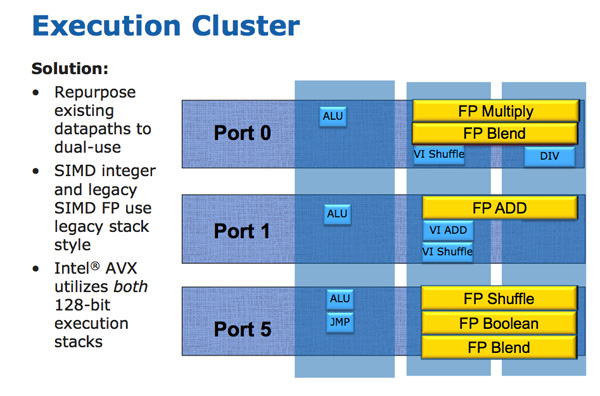
深谷白云 发表于 2010-11-13 21:40
也就是这张图片是fans做的所以做不得准?所以上面写的256-bit AVX不是AMD的说法?
spinup 发表于 2010-11-14 12:48
nehalem
sandybridge
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

