

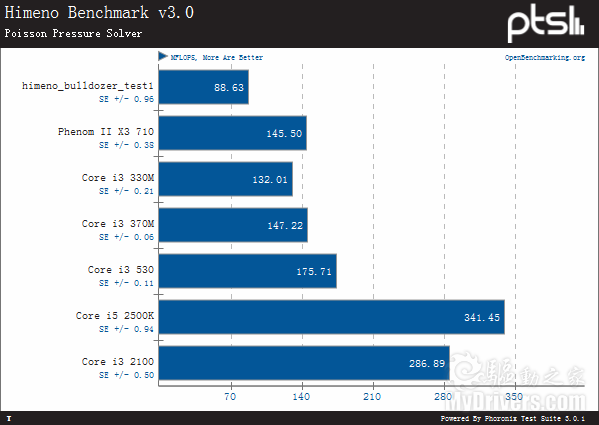
Parallel BIZP2并行文件压缩测试:推土机平台表现很不错,只用了6.27秒钟。   这就是目前能够确认属实的推土机性能表现了,稍后肯定还会有更多秘密浮现。虽然这里只是服务器端的数据,而且都是在Linux系统下完成的,但总算是第一份来自第三方的独立测试结果,权当管中窥豹吧。 |
Jason21 发表于 2011-3-23 15:17
如果成绩好,早就爆出来了
hoolay 发表于 2011-3-23 16:20
32核心被24核心秒了。。。。。AMD你别这样啊。。。。
深谷白云 发表于 2011-3-23 17:22
4颗Xeon X7550是32核心,这小编的水准……
elisha 发表于 2011-3-23 20:48
32核对32核,速度慢一半啊
acqwer 发表于 2011-3-23 16:12
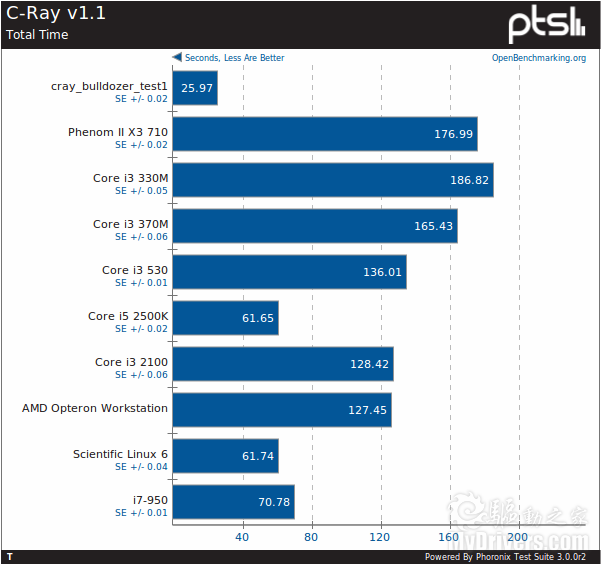
推土机 25.97*16*1.8=748
SNB 61.65*4*3.3=814
推土机一个模块超过了SNB一个核心,性能挺不错。
河蟹万岁 发表于 2011-3-23 22:26
很多人说推土机单线程相比K10性能不强,并非如此,把推土机每模块多出来的那个核当成“大号HT”就好理解了。 ...
冰灵鬼 发表于 2011-3-23 22:30
都没样片出来,这么多专家有多少明确了解推土机怎么执行“单线程”的?!
河蟹万岁 发表于 2011-3-23 22:36
一个模块
单线程,前端资源会有剩;双线程,整数运算单元资源会有剩。整体来讲,是资源利用度高的方法。
...
itany 发表于 2011-3-23 21:43
我算了一下,1.0G单核的性能指数:
Bulldozer - 6.69e-4
Sandy 2500K - 12.29e-4
gtx5 发表于 2011-3-23 22:48
频率差了多少?
河蟹万岁 发表于 2011-3-23 22:46
笑看某楼酸溜溜
我又没跟INTEL比,跟K10比而已。
单线程只能用到前端一半资源,那就没必要绑成一个模块了 ...
河蟹万岁 发表于 2011-3-23 22:53
回复 itany 的帖子
两个ALU两个管线就满足了?
河蟹万岁 发表于 2011-3-23 22:58
回复 itany 的帖子
“HT情况下一个核心全部资源都能投放在一个线程上”,那开了HT,两个线程比单核单线程多 ...
河蟹万岁 发表于 2011-3-23 23:09
回复 itany 的帖子
具体到按摩店为何非要绑成模块,我不清楚。
CC9K 发表于 2011-3-23 23:20
另外推土机是单个整数核心是独立4条管线(2个ALU+2个AGU),可以满足吃端口4条指令的情况,K10虽然是3个ALU ...
itany 发表于 2011-3-23 23:26
管线的宽度使用x86指令来算的,不是用微操作或者宏操作来计算的。
涉及内存操作的x86译码之后就变成两个 ...

itany 发表于 2011-3-23 23:02
当然是凭空的,为什么不是凭空的呢?
你知不知道什么叫做相关性? 知不知道什么叫做分支预测/内存预读失 ...
cogitata 发表于 2011-3-24 10:15
这个关键点被很多人忽略了
itany 发表于 2011-3-23 22:40
一个Bulldozer执行单元就两个ALU,正好对应的救赎双发射的前端,和Bobcat一样,要四发射做什么?
请问? ...
Prescott 发表于 2011-3-24 11:02
内存测试成绩严重偏低我不否认,但是,动不动就1/20也太夸张了。这个系统STREAM测试都到1xGB/s了,Xeon系 ...
futchi 发表于 2011-3-24 12:18
每个magny cours处理器都是4通道的,4路16通道ddr3-1333内存的内存带宽当然大得惊人。反观这个8通道ddr ...
Prescott 发表于 2011-3-24 12:59
扯蛋!magny cours也是四通道,两个CPU一共八通道,和这个被测试的推土机平台一模一样。magny cours也只跑 ...
ifu 发表于 2011-3-24 11:38
很浅显的道理,宽指令发射窗口有助于提高指令执行的并行度。
河蟹万岁 发表于 2011-3-24 07:05
似乎你这个“流水线阻断”的时候,某个线程等待,相对就有闲置资源,这个闲置资源这个线程是无法用的, ...
河蟹万岁 发表于 2011-3-24 06:38
貌似在哪看到过,问会不会因为ALU减少,单核性能下降。
回答是,K10的六个单元本来就有多,五个就够了,为 ...
冰灵鬼 发表于 2011-3-23 22:30
都没样片出来,这么多专家有多少明确了解推土机怎么执行“单线程”的?!
hammerking 发表于 2011-3-24 22:18
事实?看着严重偏低的内存子系统性能得出推土机悲剧的结论,不是事实,是偏见~
hammerking 发表于 2011-3-24 22:18
事实?看着严重偏低的内存子系统性能得出推土机悲剧的结论,不是事实,是偏见~
| AMD以前YY-----------AMD將會在美國時間5/14中午12:01公佈四核心Opteron「Barcelona」,毫無意外的,AMD預定公佈的效能測試,就是之前說過的「SPEC CPU 2006的整數浮點輸出率個別領先21%和50%」,比較基準是兩顆時脈2.6GHz的Opteron 2272SE和兩顆2.66GHz的Xeon DP x5355。 根據AMD的說法,x5355的數據來自4/16登錄在SPEC網站的資料(啊,繼去年在IDF被公開斬首示眾的Sun,這次換Fujitsu倒楣了): CINT2006 Rates Barcelona 2.6GHz(2272SE)x2:104 Clovertown 2.66GHz(x5355)x2:82.2 CFP2006 Rates Barcelona 2.6GHz(2272SE)x2:92 Clovertown 2.66GHz(x5355)x2:60.6 |
PRAM 发表于 2011-3-24 22:40
是的,每次都相信AMD比INTEL领先20%的信息的不是事实,是偏见
hammerking 发表于 2011-3-24 22:18
事实?看着严重偏低的内存子系统性能得出推土机悲剧的结论,不是事实,是偏见~
hammerking 发表于 2011-3-24 23:37
那就mark一下了,8模块interlgos对8核snb-e~
hammerking 发表于 2011-3-24 23:37
那就mark一下了,8模块interlgos对8核snb-e~
hammerking 发表于 2011-3-24 23:32
哈哈,你也真够无聊,也真够敬业的~!懒得跟你这样的折腾了~
futchi 发表于 2011-3-25 09:31
貌似intel都不准备出桌面版8核sb-e了。
至于xeon sb-ex 8核,intel并不会把它作为最高端,32nm最高端x ...
potomac 发表于 2011-3-25 12:24
A能超过intel的10C么?
futchi 发表于 2011-3-25 15:00
k10.5单核同频性能是westmere的70%左右,12核magny cours@ 2.3GHz相比于10核westmere @ 2.4GHz:
70%x ...
Prescott 发表于 2011-3-24 23:26
得出推土机杯具的结论还需要看这个测试?
一个模块能打得过Romley-R平台一个core就算是AMD成功。
futchi 发表于 2011-3-25 15:00
k10.5单核同频性能是westmere的70%左右,12核magny cours@ 2.3GHz相比于10核westmere @ 2.4GHz:
70%x ...
acqwer 发表于 2011-3-25 22:16
up to 50%和50%是2个概念,如果算up to的话,Core2 Nahelem SNB的提升幅度都可以写up to 100%
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

