
 不过3g显存很吓人的说
不过3g显存很吓人的说 感谢分享,静等实物
感谢分享,静等实物
solidusmic 发表于 2011-12-22 10:50
性能技术都是扯淡
价格才是关键
disruptor 发表于 2011-12-22 11:25
哦,大概明白了。
我感觉和gf100主要的区别是1:16个simd打包成一组,每组分配一个64kBYTE的向量寄存器外加 ...
Edison 发表于 2011-12-22 13:14
其实 Fermi 也是 16 个一"组",看架构图就知道了,一组一个硬件线程。
http://www.pcinlife.com/article ...
 e大的好文章 来学习
e大的好文章 来学习Edison 发表于 2011-12-22 13:14
其实 Fermi 也是 16 个一"组",看架构图就知道了,一组一个硬件线程。
http://www.pcinlife.com/article ...
panjanstoneborg 发表于 2012-1-7 00:20
问一下图元primitive是不是指三角形
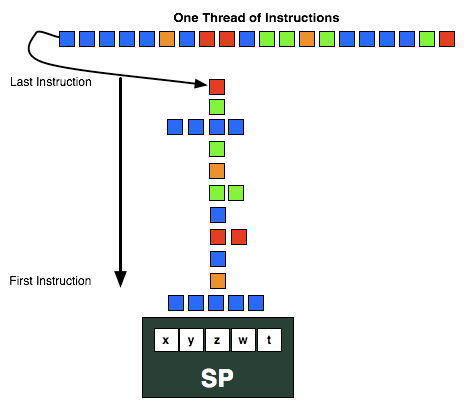

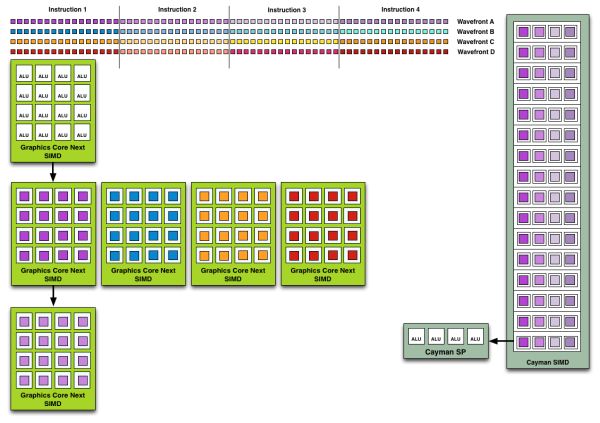
Edison 发表于 2012-1-7 14:53
这个图只是说 Cayman 会尝试同时执行同一个 Wavefront 里的不同指令,而 GCN 则可以同时跑不同的 wavefront ...
Edison 发表于 2012-1-7 15:03
因为不可能 wavefront 里的所有指令都能实现 VLIW4。
panjanstoneborg 发表于 2012-1-7 15:09
那就是不能实现啊,这不就是vliw的缺点嘛
Edison 发表于 2012-1-7 15:12
VLIW4 还是可以有较高机会的,只要不相依。。
panjanstoneborg 发表于 2012-1-9 12:09
cu里也没有发现有agu啊?

RacingPHT 发表于 2012-1-10 11:20
3.5倍能达到吗?



| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

