

w7231665 发表于 2012-2-11 18:13
按这个规格- -灭7XXX全家真是没压力了
蕊珠 发表于 2012-2-11 19:19
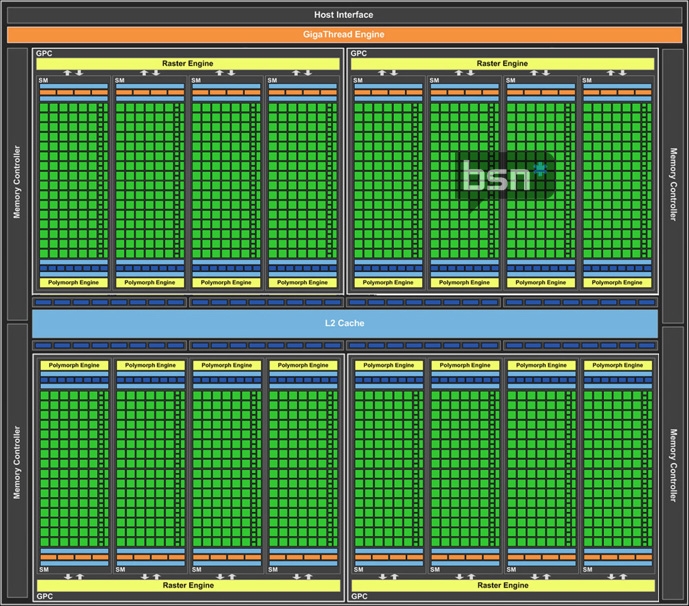
此1536非fermi时代的sp,GK104 1536sp,950M主频,达到的单精度浮点运算是2.918T的话,只能说明GK104构架 ...
蕊珠 发表于 2012-2-11 19:19
此1536非fermi时代的sp,GK104 1536sp,950M主频,达到的单精度浮点运算是2.918T的话,只能说明GK104构架 ...
66666 发表于 2012-2-11 19:31
GTX580哪来的2.3T单精度?
66666 发表于 2012-2-11 19:31
GTX580哪来的2.3T单精度?
66666 发表于 2012-2-11 19:31
GTX580哪来的2.3T单精度?
蕊珠 发表于 2012-2-11 19:41
NV核心单精度浮点运算的计算公式是流处理器频率*3*流处理器数量,当初GTX280的规格是240sp,流处理器频率 ...
蕊珠 发表于 2012-2-11 19:41
NV核心单精度浮点运算的计算公式是流处理器频率*3*流处理器数量,当初GTX280的规格是240sp,流处理器频率 ...
66666 发表于 2012-2-11 19:53
恩恩,原来NV自己公布的1.5T是胡扯,您自己YY的2.3T才正确是吧?
你所谓的计算公式依据在哪?有CUDA程 ...
蕊珠 发表于 2012-2-11 20:12
280的浮点运算就是0.933T了,580才1.5T你觉得靠谱吗?要用脑子想想,不要光相信别人的答案,当然2.9如果也 ...
sunstarmoon 发表于 2012-2-11 20:12
因为根据官方数据套进你自己想出来的公式计算出来的结果不符合现实情况,所以错的是NV公布出来的数据不是 ...
蕊珠 发表于 2012-2-11 20:12
280的浮点运算就是0.933T了,580才1.5T你觉得靠谱吗?要用脑子想想,不要光相信别人的答案,当然2.9如果也 ...

66666 发表于 2012-2-11 20:15
这个“别人”可是NV自己好吧,我只见过把自家产品技术参数虚报高的
可从没见过故意往低的报的公司
sunstarmoon 发表于 2012-2-11 20:25
单精度浮点不是有公式算的么。。是nv能随口乱说的吗。。。
就算是GF114与GF110的公式也略有不同,更不用 ...
蕊珠 发表于 2012-2-11 20:25
用来计算显卡性能的浮点运算反正不能用NV的数据,用我这种方法算出来的和实际符合很好。
还有一个例子, ...
66666 发表于 2012-2-11 20:35
和什么实际符合的很好?实际哪个应用或者测试软件能得到你所谓2.3T单精度?
蕊珠 发表于 2012-2-11 19:41
NV核心单精度浮点运算的计算公式是流处理器频率*3*流处理器数量,当初GTX280的规格是240sp,流处理器频率 ...
Edison 发表于 2012-2-11 20:41
你对 Tesla 和 Fermi 的架构认识不够清楚。
GT200 可以让所有的 cuda core 再加上 SFU 实现 8 cuda co ...
蕊珠 发表于 2012-2-11 20:53
但按照1.5T的浮点运算是算不出与实际相符的理论性能的,只有按照2.372T算才与实际性能相符,我们可以定 ...
Edison 发表于 2012-2-11 21:06
NVIDIA 对 GPUBench 的 RCP 函数计算一直有些特殊的优化,所以不要指望拿 GPUbench 出来的 rcp 测试结果作为 ...
蕊珠 发表于 2012-2-11 21:13
我计算用的实际性能是从各大评测网站评测报告算得的综合性能,由于各种因素,实际性能不会严格等于理论 ...
Edison 发表于 2012-2-11 21:19
你用各个网站的性能报告来综合这个我不关心,关键是你依据这个来说 GPU 理论峰值的计算方式有问题就是错误 ...
Edison 发表于 2012-2-11 21:19
你用各个网站的性能报告来综合这个我不关心,关键是你依据这个来说 GPU 理论峰值的计算方式有问题就是错误 ...
蕊珠 发表于 2012-2-11 20:53
但按照1.5T的浮点运算是算不出与实际相符的理论性能的,只有按照2.372T算才与实际性能相符,我们可以定 ...
spring62 发表于 2012-2-11 21:23
你是不是应该考虑推土机和2500k的游戏表现然后给出一个推土机的实际核心数/频率?
N和A的计算能力在游戏 ...
蕊珠 发表于 2012-2-11 21:22
我说了我计算用的理论峰值可能不是NV所谓的单精度浮点运算,而可以定义为理论游戏运算性能。
NV核心单精度浮点运算的计算公式是流处理器频率*3*流处理器数量,当初GTX280的规格是240sp,流处理器频率1296M,算的单精度浮点运算为0.933T,与标称相符。用这种方法算得580单精度浮点运算是2.372T,和标称不符
Edison 发表于 2012-2-11 21:27
这可是你前面说的,你这样的说法就体现了你对 NVIDIA 架构并不了解,在这样的情况下弄出来的理论性能怎 ...
蕊珠 发表于 2012-2-11 21:29
我理论计算的和实际的都列在那个帖子里面了,里面不准确吗?

Edison 发表于 2012-2-11 21:47 修正理论值计算方式后,足以让你的斜率截然不同。
lik 发表于 2012-2-12 01:38
NV的单精度浮点峰值不就是简单公式 cuda core数量 (就是传统的MAD运算单元) * shader 频率 * 2 吗? 哪有那么 ...
Edison 发表于 2012-2-11 21:27
这可是你前面说的,你这样的说法就体现了你对 NVIDIA 架构并不了解,在这样的情况下弄出来的理论性能怎 ...
蕊珠 发表于 2012-2-12 12:36
这个问题可以这样来叙述,GTX280的单精度浮点运算值是0.933T,而显存带宽是141.7G,实际性能值为106.1;G ...
夏天的风 发表于 2012-2-12 12:39
我真觉得你不是一般的奇葩,明明就是自己的神棍公式有问题,非要说官方给出的数据是错的,非要说自己算出 ...
Edison 发表于 2012-2-12 12:55
Tesla 20 的 dual-issue 只有在常见算术指令+MUL 的情况下才能实现,例如 MAD+MUL、ADD+MUL、MUL+MUL,它无 ...

蕊珠 发表于 2012-2-12 12:02
GTX280的计算公式却是流处理器频率*流处理器数量*3
蕊珠 发表于 2012-2-12 12:36
这个问题可以这样来叙述,GTX280的单精度浮点运算值是0.933T,而显存带宽是141.7G,实际性能值为106.1;G ...
蕊珠 发表于 2012-2-12 13:02
可以抽象出一个理论游戏计算性能出来,理论值与实际值肯定有偏差,但是能反应大致情况,而且对以往显卡的 ...
。oh my ladygaga!| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

