餐具 发表于 2012-3-23 18:58
通用计算要有个生态圈的,性能有个蛋用


餐具 发表于 2012-3-23 18:58
通用计算要有个生态圈的,性能有个蛋用
 对我来说可以挖坟
对我来说可以挖坟 
CC9K 发表于 2012-3-23 19:09
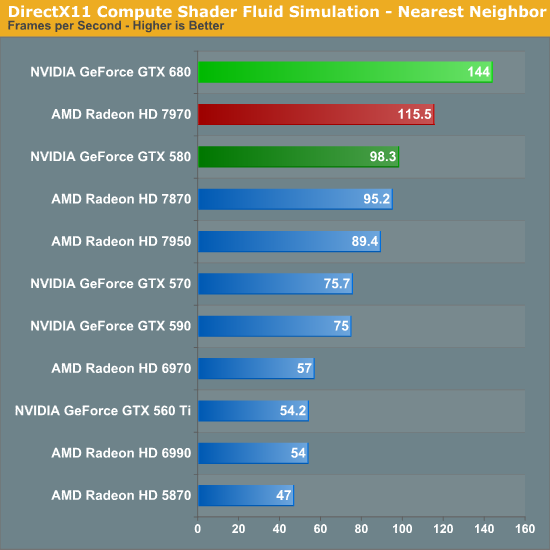
ZOL测试通用计算性能680能秒了7970

CC9K 发表于 2012-3-23 19:09
ZOL测试通用计算性能680能秒了7970
大炮村的小编放评测前就说了
CC9K 发表于 2012-3-23 19:09
ZOL测试通用计算性能680能秒了7970

yihua伊华 发表于 2012-3-23 20:09
是不是这就是传说中的伪电,好,你GCN 7970大玩通用计算,我先不跟你玩,出个玩家叫好的游戏卡压死你,奈何 ...
伪电到领先4% 我是吐了yihua伊华 发表于 2012-3-23 20:09
是不是这就是传说中的伪电,好,你GCN 7970大玩通用计算,我先不跟你玩,出个玩家叫好的游戏卡压死你,奈何 ...
CC9K 发表于 2012-3-23 22:57
显卡吧多欢乐
GTX999 发表于 2012-3-23 18:53
某个2盘菜曾经点评我说他测的通用计算680完爆7970
挖太多了 让他休息休息

VOODOO亚麻得 发表于 2012-3-24 02:30
但你胡乱扯就是你的不对,又是菜又是谍战片的,洋相都被你出尽了,让人感觉680很牛逼,最后是托屎

VOODOO亚麻得 发表于 2012-3-24 02:33
你胡乱扯就是你的不对,让N饭失望,让AMD得意,你怎么能叫N饭?你让大家情何以堪
VOODOO亚麻得 发表于 2012-3-24 02:34
你不去当神棍都吃亏了,肯定能骗很多人得,这次你在PCI让人很心寒,你已经失宠了,不多说了
VOODOO亚麻得 发表于 2012-3-24 02:34
你不去当神棍都吃亏了,肯定能骗很多人得,这次你在PCI让人很心寒,你已经失宠了,不多说了
VOODOO亚麻得 发表于 2012-3-24 02:36
你继续吃你的两盘菜吧,主子给你的钱只够吃路边摊的也怪可怜的
VOODOO亚麻得 发表于 2012-3-24 02:37
你现在在PCI都成过街老鼠了,你暗自得意吧,你自己心里清楚忽悠了多少人,说真的你的文章写出来也是奇迹, ...
VOODOO亚麻得 发表于 2012-3-24 02:41
我封不封没关系,但你没发现现在很多人在挖你坟么?你感觉是光荣的事?
VOODOO亚麻得 发表于 2012-3-24 02:55
别的不说了,反正感觉你这次是两边都不讨好,不过680烧了那么多真的是680质量问题?
围观某楼被喷硬抗 哈哈哈CC9K 发表于 2012-3-23 22:57
显卡吧多欢乐
 除非点中了月神的所谓伪电
除非点中了月神的所谓伪电BDFMK2 发表于 2012-3-24 09:31
文明5不是纯吞吐测试吧?
纯吞吐的话,GK104应该有优势才对
mooncocoon 发表于 2012-3-24 22:49
就目前的情况来看,GK104在很多场合的FP吞吐甚至只有Tahiti的一半……NV这次驱动过于仓促了。

aixiangsui2012 发表于 2012-3-24 23:01
DP更叫人揪心。。。三分之一到七分之一
PS:
这次NV以为AMD又会玩老招数,结果防范过头了。

darkstorm 发表于 2012-3-23 19:07
通用计算和游戏不同,相互之间区别很大,而且非常单纯,一般就是某种存储器上。
瓶颈出现在指令上是好的情 ...
CC9K 发表于 2012-3-24 23:51
原来并行计算可以无视吞吐量的?
其实GT430也只是吞吐量不如480而已,除开吞吐量性能和GTX480是一样的
mooncocoon 发表于 2012-3-24 23:09
以我的测试,GK104的MAD DP吞吐是SP的1/4,很稳定……我不知道该不该相信,除了继续痛骂NV驱动仓促之外好 ...

mooncocoon 发表于 2012-3-25 11:44
吞吐只有在“有效”的前提下才有意义啊,吞进去跑一圈无效出来在打一次包吞一次,这样造就出来的吞吐量对 ...

mooncocoon 发表于 2012-3-24 02:24
刚看到这贴……然后开始后悔看到了……
纯吞吐测试=通用计算性能测试……你咋不去找找bitcoin的测试啊~那个 ...
CC9K 发表于 2012-3-25 12:28
你说有效就有效,无效就无效喽,全世界680对7979的通用运算测试都是无效单元动作,跑了几圈得出个无效的测 ...
los_parrot 发表于 2012-3-25 12:23
跟驱动没有多少关系,gk104本来运算能力就不如tahiti,有这种结果是正常的.
mooncocoon 发表于 2012-3-25 14:05
果然我又无效吞吐了
而且果然又疯了一只啊[sweatingbullets>
los_parrot 发表于 2012-3-25 12:23
跟驱动没有多少关系,gk104本来运算能力就不如tahiti,有这种结果是正常的.
aixiangsui2012 发表于 2012-3-25 16:31
单精度方面,NV已经有所落败,双精度方面,NV和A卡天差地别。
这种状况是怎么产生的呢,有帖子这么说的:
...
CC9K 发表于 2012-3-25 14:43
搞清楚自己的状况好么?
是你们的测试结论与全世界主流测媒体的结果相悖
樟树 发表于 2012-3-25 15:06
I/D cahce 自古以来就是分离的...
如果把I$做成和shared/L1 data一样的结构要慢死...
mooncocoon 发表于 2012-3-25 17:13
MS要求shared这种东西存在,那最经济的做法其实就是这么干了,Fermi和Tahiti都是这么干的。
至于I/D分 ...
樟树 发表于 2012-3-25 17:15
I/D cache自远古以来就是分离的...
从来没有在一起过
更没有在Fermi上在一起过...


樟树 发表于 2012-3-25 17:31
这段话来自你的文章,其中除了L1 cache和shared共享空间以外,都是错的:
"在费米构架中,NVIDIA引入的第一 ...

mooncocoon 发表于 2012-3-25 17:38
L1 cache采用统一格式同时与shared分享空间,所有指令和数据均通过两者共同缓冲
这句话依旧后面的描述的 ...
Edison 发表于 2012-3-25 18:09
我建议你把这段全部删除。
我要留着,而且还要加上“CHO某对我说”。樟树 发表于 2012-3-25 16:51
不对
主要原因很简单,就是双精度运算单元不够
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
