itany 发表于 2012-11-4 16:54
坐等T神如何回应~~
itany 发表于 2012-11-4 16:54
坐等T神如何回应~~
Tempestglen 发表于 2012-11-4 17:28
如果跑分程序完美支持超线程,那么1.8GHz A15 2C2T=1.8Ghz Atom 2C4T
问题是支持超线程的跑分程序也是 ...
Tempestglen 发表于 2012-11-4 17:28
如果跑分程序完美支持超线程,那么1.8GHz A15 2C2T=1.8Ghz Atom 2C4T
问题是支持超线程的跑分程序也是 ...
acqwer 发表于 2012-11-5 09:08
手机版的A15还在火星,单核1.7G就能上到5W的功耗,按T神的频率-功耗算法,对于2W功耗下跑到2G频率的ATO ...
Tempestglen 发表于 2012-11-4 17:28
如果跑分程序完美支持超线程,那么1.8GHz A15 2C2T=1.8Ghz Atom 2C4T
问题是支持超线程的跑分程序也是 ...
Tempestglen 发表于 2012-11-5 11:11
geekbench支持超线程,我拿出来比较,就已经算是开恩了,实际软件pk,A15优势更大。
你的余下的全是废话 ...

Tempestglen 发表于 2012-11-5 11:11
geekbench支持超线程,我拿出来比较,就已经算是开恩了,实际软件pk,A15优势更大。
你的余下的全是废话 ...
itany 发表于 2012-11-5 13:59
秒A15只需要1G的Haswell性能,而Haswell是3-4G [titter>
实际上如果应用都是单线程的,那你家Arm搞四核 ...
Tempestglen 发表于 2012-11-5 11:11
geekbench支持超线程,我拿出来比较,就已经算是开恩了,实际软件pk,A15优势更大。
你的余下的全是废话 ...
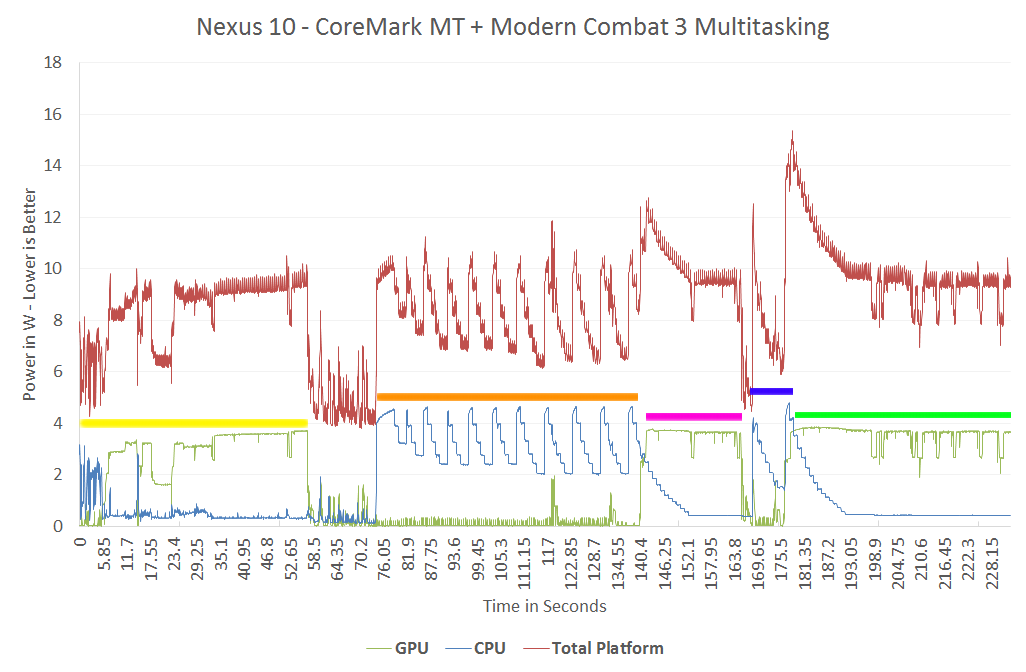
Tempestglen 发表于 2013-1-28 13:59
惊喜看到很多坟,exynos5250的tdp不是8w了嘛,怎么没爆炸?性能也不是0啊。
开普勒 发表于 2013-1-28 13:56
居然没有人反汇编来吐槽一下?
用objdump反汇编libgeekbench-jni.so,以Mandelbrot测试项目为例:
Tempestglen 发表于 2013-1-28 14:05
猪神,你家atom的sun spider被日了,哈哈。
itany 发表于 2013-1-28 14:06
果然没有矢量化啊
the_god_of_pig 发表于 2013-1-28 14:12
这个ARM也是标量阿,x86的SIMD效率会比NEON高很多?
the_god_of_pig 发表于 2013-1-28 14:12
这个ARM也是标量阿,x86的SIMD效率会比NEON高很多?
开普勒 发表于 2013-1-28 14:26
A15有两条流水线可以执行NEON指令(而且跟VFP共用),对fp32来说每条可以处理两个lane。但是,一部分NEON ...
the_god_of_pig 发表于 2013-1-28 14:37
多谢科普
没记错的话atom SIMD单次吞吐量是128bit,执行4个单精度,不过这是理论值,主要还是看实测NE ...
开普勒 发表于 2013-1-28 14:55
微架构的东西最好用小程序实测
比较标量浮点的话,个人认为A15的效率是相当高的:两条VFP流水线+乱序 ...
Tempestglen 发表于 2013-1-28 13:59
惊喜看到很多坟,exynos5250的tdp不是8w了嘛,怎么没爆炸?性能也不是0啊。
Tempestglen 发表于 2013-1-28 15:38
是滴!
Tempestglen 发表于 2013-1-28 15:43
没有矢量化的条件下,atom浮点已经惨败给swift 和A15;如果开启矢量化,那要看neon和sse的效率了。不过既 ...
Tempestglen 发表于 2013-1-28 14:03
单核A15@1.7Ghz就是5w吗?坟
Tempestglen 发表于 2013-1-29 09:31
你预测了5w,我预测了3w,然后实测结果是4w,所以你预测基本准确,我的预测就是扯蛋。
Tempestglen 发表于 2013-1-29 09:31
你预测了5w,我预测了3w,然后实测结果是4w,所以你预测基本准确,我的预测就是扯蛋。
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

