Tempestglen 发表于 2013-1-22 10:51
i棍一厢情愿的yy。
arm阵营28nm LPH对于32nm LP的改进大于intel的32nm->22nm。
Tempestglen 发表于 2013-1-22 10:51
i棍一厢情愿的yy。
arm阵营28nm LPH对于32nm LP的改进大于intel的32nm->22nm。
Tempestglen 发表于 2013-1-22 10:51
i棍一厢情愿的yy。
arm阵营28nm LPH对于32nm LP的改进大于intel的32nm->22nm。
Cherbim 发表于 2013-1-22 14:12
half-node改进都大于full-node,三木桑无敌的火星工艺啊,真这样的话Intel这40年白混了
Cherbim 发表于 2013-1-22 14:12
half-node改进都大于full-node,三木桑无敌的火星工艺啊,真这样的话Intel这40年白混了
Tempestglen 发表于 2013-1-22 14:23
是三棒原来的32nm太烂而已。
Tempestglen 发表于 2013-1-22 14:23
是三棒原来的32nm太烂而已。
Prescott 发表于 2013-1-22 11:16
早就说过:如果ARM把功耗拉到1W以下和Intel打超轻量级拳击,Intel还是比较心虚的,没有体重那么轻的选手啊, ...
slice 发表于 2013-1-22 14:45
你以为ARM想啊,增这么点性能,功耗就爆棚了,只好有回头搞A7挽回下面子。
至于说1w以下,A7倒是可以搞搞 ...
frankincense 发表于 2013-1-22 14:58
Oact能比5250省电就要烧香拜佛了
当然强行功耗限制还是可行的
slice 发表于 2013-1-22 15:03
看起来人高马大,宣传的可是8核YEAH!!,一上床就萎了。
5250不就是最大8w+,给强制压在4w了么。
Prescott 发表于 2013-1-22 11:16
早就说过:如果ARM把功耗拉到1W以下和Intel打超轻量级拳击,Intel还是比较心虚的,没有体重那么轻的选手啊, ...
itany 发表于 2013-1-22 16:02
未来手机电池肯定越来越NB,手机处理器在散热允许的2-3W之内进行发挥,运行功耗小了也没意义。
Intel也没 ...
Prescott 发表于 2013-1-22 17:07
2-3W其实体验已经不好了。
G70 发表于 2013-1-22 18:06
a15就靠t神的嘴炮工艺了
westlee 发表于 2013-1-22 20:00
能量密度翻番的电池短期内不现实吧。
potomac 发表于 2013-1-22 20:47
功耗下来是可以做到的。
比如把芯片做大,而不是频率拉高。
这点对intel特别容易,

potomac 发表于 2013-1-22 20:54
那是因为没风扇,老黄的演示都坚持不下来。
如果是产品,不可能有。(并且99.99%不会有产品。)[tongue>
guobacoo 发表于 2013-1-23 10:10
频率开低点再试试
Tempestglen 发表于 2013-2-26 08:21
我当然有种,就看i狗的单核1Ghz haswell有没有种和Tegra4 PK性能了。
这里面多线程测试也就 browsermark ...
Tempestglen 发表于 2013-2-26 08:21
我当然有种,就看i狗的单核1Ghz haswell有没有种和Tegra4 PK性能了。
这里面多线程测试也就 browsermark ...
itany 发表于 2013-2-26 10:22
别人早就指出Geekmark在x86上边使用的是没有矢量化的SSE,根本就是劣化x86性能
如果x86不矢量化,Arm也不 ...
Tempestglen 发表于 2013-2-27 08:25
haswell 单核 1Ghz 1500以上
Tegra4 单核1.9Ghz 1168,四核的话X3,大概3500.
Tempestglen 发表于 2013-2-27 08:28
你还要不要脸? geekbench测试,arm根本没有用neon,大家都是pk标量浮点,你这是明知故问。
Tempestglen 发表于 2013-2-27 08:25
haswell 单核 1Ghz 1500以上
Tegra4 单核1.9Ghz 1168,四核的话X3,大概3500.
itany 发表于 2013-2-27 10:13
T 神过了两天还是分不清什么是SPECint,什么是SPECint rate么
Tempestglen 发表于 2013-2-27 10:34
单线程的specint 2000, A15@ 1.9Ghz是1168分。
多线程的specint RATE, 四核 A15@ 1.9Ghz是3500分=3倍 ...
Tempestglen 发表于 2013-2-27 10:40
分三局,三局两胜。
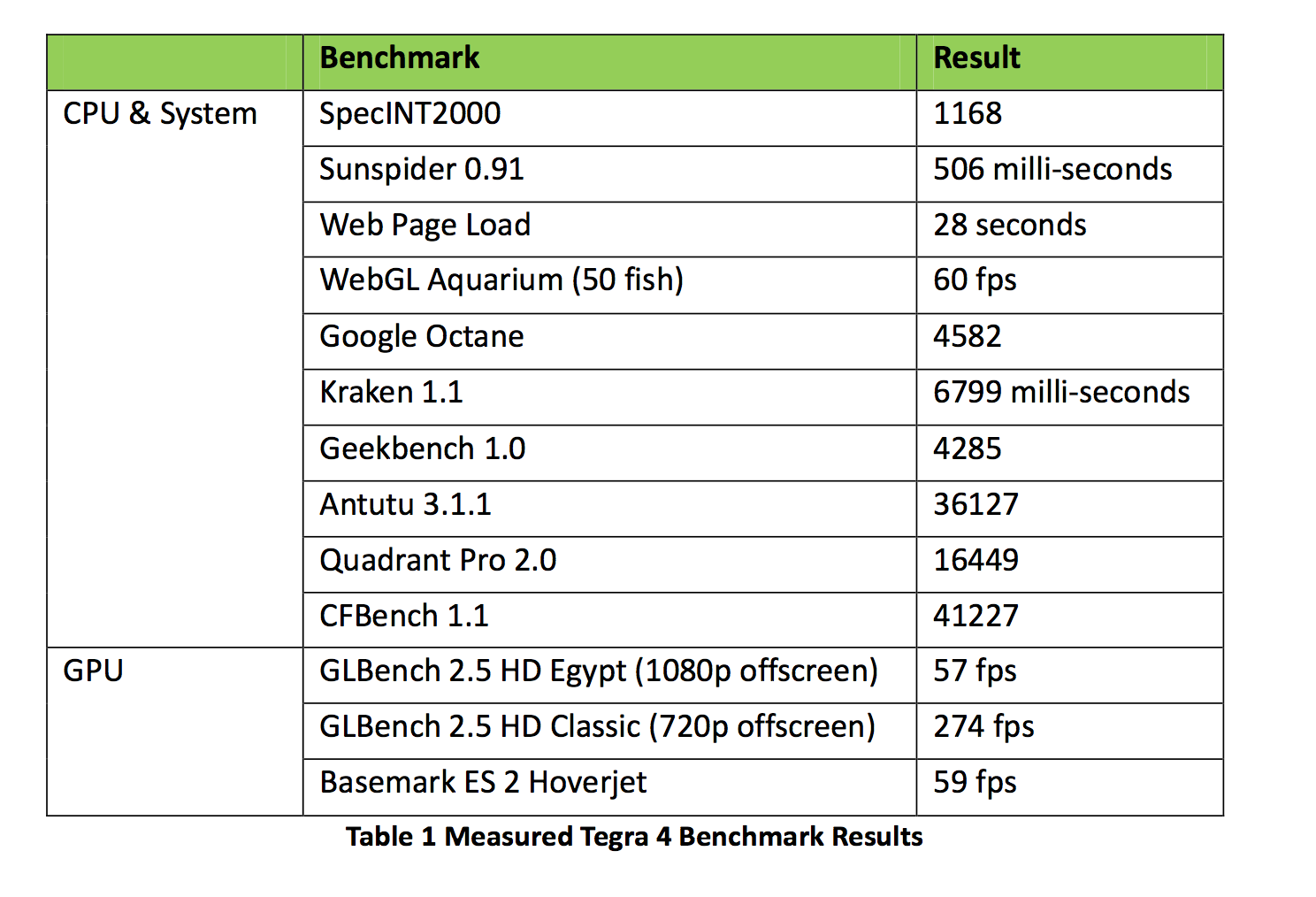
Tempestglen 发表于 2013-2-27 11:04
这些cpu测试项目,除了geekbench和antutu,quadrant其余大概都是侧重单线程测试。octa跑那些js测试的时候 ...
Tempestglen 发表于 2013-2-27 11:13
Tegra4 的spec int RATE的3500分不是给你了吗?
你觉得我的计算有问题可以提出来,不要拐弯抹角。
Airhouse 发表于 2013-2-27 11:44
你到现在还不明白specint和spectint_rate的区别?你贴的图是specint, specint_rate完全是另外一个级别的 ...
frankincense 发表于 2013-2-27 11:39
T神你知道SPECint2000 Rates 3500分是什么概念么?
1.6G的Intel Itanium 9050能跑出4200分多,是SPECint20 ...
raini 发表于 2013-2-27 11:53
ARM是拥有天顶星技术的公司,特别有着T字头SB弱智神当新闻官,
所以地球上的公司是不能比的!
这下不是 ...
Airhouse 发表于 2013-2-27 11:44
你到现在还不明白specint和spectint_rate的区别?你贴的图是specint, specint_rate完全是另外一个级别的 ...
frankincense 发表于 2013-2-27 11:55
600%?3500分直接i5 3570K的12倍妥妥的
Tempestglen 发表于 2013-2-27 12:33
Specint 这种单线程测试1168 分 对1500分。
如果用单核去跑spec rate多线程测试,还是不是1168:150 ...
Tempestglen 发表于 2013-2-27 12:33
Specint 这种单线程测试1168 分 对1500分。
如果用单核去跑spec rate多线程测试,还是不是1168:150 ...
Tempestglen 发表于 2013-2-27 12:33
Specint 这种单线程测试1168 分 对1500分。
如果用单核去跑spec rate多线程测试,还是不是1168:150 ...
Tempestglen 发表于 2013-3-1 16:39
年底的时候,高频/多核swift已经虐了A15,A57也会在几个月后来到。
silvermont和temash还是想想怎么 ...
Tempestglen 发表于 2013-3-1 16:39
年底的时候,高频/多核swift已经虐了A15,A57也会在几个月后来到。
silvermont和temash还是想想怎么 ...
largewc 发表于 2013-3-1 17:14
swift应该性能没有标版a15更好,那个玩意只是阉割版本而已,ios因为封闭,所以指令集可以固死thumb2,性能 ...
itany 发表于 2013-3-1 18:47
安卓不是执行的本地代码,而是运行在虚拟层上边吧,这也是大多数安卓程序能够直接上x86的原因,效率自然比 ...
itany 发表于 2013-3-1 18:47
安卓不是执行的本地代码,而是运行在虚拟层上边吧,这也是大多数安卓程序能够直接上x86的原因,效率自然比 ...
largewc 发表于 2013-3-1 18:53
现在wp本地代码程序很少,wp7就是输在不支持本地代码上的
安卓成功,很大的程度就是因为2.1以后,ndk开 ...
itany 发表于 2013-3-1 18:47
安卓不是执行的本地代码,而是运行在虚拟层上边吧,这也是大多数安卓程序能够直接上x86的原因,效率自然比 ...
itany 发表于 2013-3-1 18:56
谢谢指教~
itany 发表于 2013-3-1 18:47
安卓不是执行的本地代码,而是运行在虚拟层上边吧,这也是大多数安卓程序能够直接上x86的原因,效率自然比 ...
largewc 发表于 2013-3-1 19:00
简单解释一下吧,一个简单指令在arm thumb 和 thumb-2还有x86的差距
int a = 0x12345678;
itany 发表于 2013-3-1 20:09
Arm居然只能分成两个16位给32位寄存器赋值?
指令长度不够,放不下32位操作数??
largewc 发表于 2013-3-1 20:24
thumb-2是两条,arm thumb都是若干条……]
arm是定长32位,而且还必须thumb-2才能组合两个16bit,诡 ...
largewc 发表于 2013-3-1 20:24
thumb-2是两条,arm thumb都是若干条……]
arm是定长32位,而且还必须thumb-2才能组合两个16bit,诡 ...
Tempestglen 发表于 2013-10-9 08:52
坐等单核1Ghz的haswell灭exynos5420,咱们比比1080p@60fps软解吧!
Tempestglen 发表于 2013-10-9 08:52
坐等单核1Ghz的haswell灭exynos5420,咱们比比1080p@60fps软解吧!

westlee 发表于 2013-10-11 19:38
找ffmpeg或者lav的源代码用icc编译下?
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |

