

dizhang 发表于 2013-2-5 12:35
大致相当于什么级别的显卡?
pikaqiuuuu 发表于 2013-2-5 12:52
游戏机环境7770级别够用了。。单就画面粗看效果肯定比pc好多了。。以跑分为乐玩游戏的时候还纠结什么贴图材 ...
 如果是真的,那么次时代主机就是比谁性能差咯,WII U和这货都没啥本质区别了
如果是真的,那么次时代主机就是比谁性能差咯,WII U和这货都没啥本质区别了qwased 发表于 2013-2-5 16:04
[titter>如果是真的,那么次时代主机就是比谁性能差咯,WII U和这货都没啥本质区别了
McQ 发表于 2013-2-5 18:55
7年多后,游戏机终于从 720P低效果 进化到 1080p中效果了
 7770还要战十年,电视游戏估计也没落了
7770还要战十年,电视游戏估计也没落了梦游的猪 发表于 2013-2-7 09:14
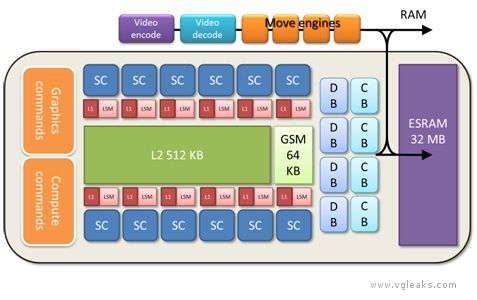
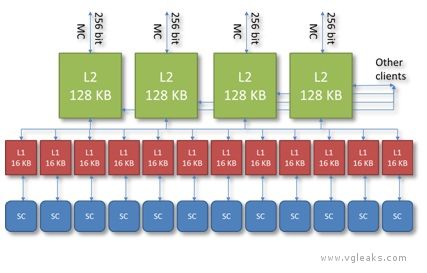
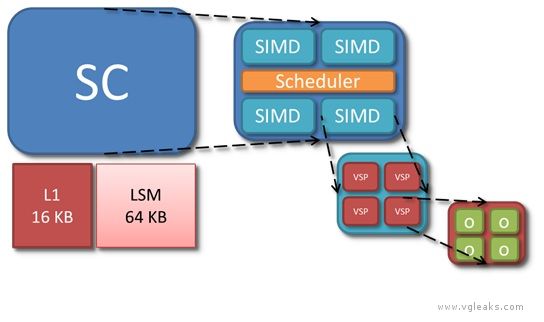
看来这一代和上一代两家的思路一致:PS4高浮点(1.8T FLOPS,估计是18组SC),X720大带宽(ESRAM)。个人还 ...
iamw2d 发表于 2013-2-7 10:27
102g/s是大带宽? 低延迟好否
goldman948 发表于 2013-2-5 16:12
当年ps3用78gt移动版时被指责为ps3性能落后的原因.
这新闻如果是真的,那还真有趣了
goldman948 发表于 2013-2-5 16:12
当年ps3用78gt移动版时被指责为ps3性能落后的原因.
这新闻如果是真的,那还真有趣了
dizhang 发表于 2013-2-5 14:59
7770的话太让人失望了啊,次时代的主机我觉得起码应该是7850这个级别的啊
sim0831 发表于 2013-2-9 11:08
X720的7770比X360的1950XT強N倍
梦游的猪 发表于 2013-2-7 14:07
1、应该是68+102吧?
2、大和小是相对的,只是7770级别的核心而已,7770带宽才72G……
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
