largewc 发表于 2013-10-30 14:44
整数比a15多了一组单元,浮点没变,6并发只是提升利用率,可能有少量的提升
这两个都不足与提供翻倍的性 ...
largewc 发表于 2013-10-30 14:44
整数比a15多了一组单元,浮点没变,6并发只是提升利用率,可能有少量的提升
这两个都不足与提供翻倍的性 ...
ifu 发表于 2013-10-30 17:01
执行单元是和指令发射端口相匹配的,见原文中four integer adds and two FP adds in parallel
在饱和吞吐 ...
largewc 发表于 2013-10-30 17:06
four integer adds and two FP adds in parallel
a15是3整数和2浮点

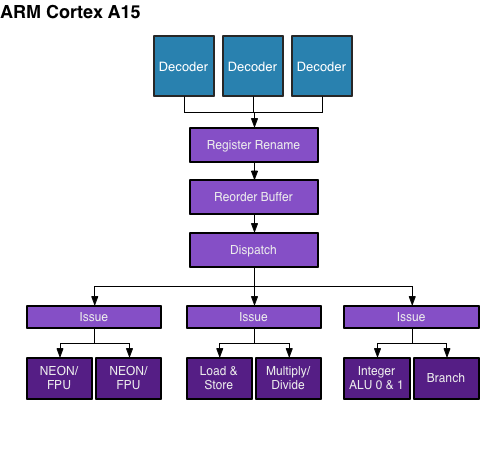
 所以堆了一个die size是a15两倍跑三滴马克物理分微增4%的玩意出来么
所以堆了一个die size是a15两倍跑三滴马克物理分微增4%的玩意出来么Tempestglen 发表于 2013-10-30 20:51
3dmark自己的程序写的不好。也根本无法体现手机平板的典型应用,与用户体验的 相关度很烂。
Tempestglen 发表于 2013-10-30 20:51
3dmark自己的程序写的不好。也根本无法体现手机平板的典型应用,与用户体验的 相关度很烂。
xf-108 发表于 2013-10-30 19:44
按照你的算法,haswell至少是8发射……
Tempestglen 发表于 2013-10-30 20:51
3dmark自己的程序写的不好。也根本无法体现手机平板的典型应用,与用户体验的 相关度很烂。
Tempestglen 发表于 2013-10-30 21:55
网页,游戏,视频回放等等。
3dmark physics,四核和大L2容量的占便宜,physics于是根本不是什么cpu计 ...
Tempestglen 发表于 2013-10-30 21:55
网页,游戏,视频回放等等。
3dmark physics,四核和大L2容量的占便宜,physics于是根本不是什么cpu计 ...
 这么说a8不上四核跟30m L2估计玩愤怒的小鸟跟百战天虫啥的“物理”游戏要卡出屎了当然L/S还是比A7强的
这么说a8不上四核跟30m L2估计玩愤怒的小鸟跟百战天虫啥的“物理”游戏要卡出屎了当然L/S还是比A7强的
Tempestglen 发表于 2013-10-31 08:16
没有一款 atom手机平板玩游戏性能超过同期ipad,你得瑟个啥?我还没来得及鄙视atom得gpu呢!
532 发表于 2013-10-31 09:33
不是啦,愤怒小鸟那么多物理特效,又没装老黄的显卡能gpu跑物理X,a7的cpu算不过来的啦,L2都卡死了我估计 ...
ifu 发表于 2013-10-31 09:30
haswell也做不到同时发射 4 INT adds+ 2 FP adds
擦才发现这标题还给高亮了,跟隔壁交易区一样黑亮给群众鞭尸围观的么小鸟那个说真的,touch4在个别场景一发KO引起太多物体崩塌的话,一样会卡,我也不晓得是不是得i7 5g跑才流畅,台式机上没玩过532 发表于 2013-10-31 10:45
[sweatingbullets>擦才发现这标题还给高亮了,跟隔壁交易区一样黑亮给群众鞭尸围观的么
[sweatingbullet ...
largewc 发表于 2013-10-31 09:41
显然a7做不到超过2浮点计算能力,不借助simd,单说浮点的话,看不到a7比a6可能更快的地方。a6三发射端口对 ...
ifu 发表于 2013-10-31 10:58
浮点本来在日常应用中所占比例就小。
haswell也只能同时发射2条浮点指令,没人会认为haswell和a6一个档次 ...
acqwer 发表于 2013-10-31 11:55
LZ又是从哪里看出A7只有一组L/S呢,莫非是Apple内部的CPU开发人员?
最起码也是官方发炎人,前些天还“在此我正式宣布a7 ipc是a6两倍”来着four integer adds and two FP adds in parallel
532 发表于 2013-10-31 11:59
[sweatingbullets>最起码也是官方发炎人,前些天还“在此我正式宣布a7 ipc是a6两倍”来着
You can also perform up to two loads or stores per clock.
acqwer 发表于 2013-10-31 12:01
这是SIMD的情况下吧
acqwer 发表于 2013-10-31 12:03
其实原文有这一句
不过砖家没看懂罢了。

acqwer 发表于 2013-10-31 11:55
LZ又是从哪里看出A7只有一组L/S呢,莫非是Apple内部的CPU开发人员?
shadowlich 发表于 2013-10-31 11:23
LZ你谈苹果就谈苹果,不要在没搞清楚的情况下就扯xbox。人家的32M ESRAM明明CPU/GPU都可以用。到你这里就成 ...

ifu 发表于 2013-10-31 12:47
同时只能2L ,2S,(1L+1S) 当然不如 haswell的2L+1S
532 发表于 2013-10-31 11:59
[sweatingbullets>最起码也是官方发炎人,前些天还“在此我正式宣布a7 ipc是a6两倍”来着
largewc 发表于 2013-10-31 11:07
haswell确实也只有两个,但是haswell支持avx,加入向量矩阵的专项指令显然可以大幅度加速3d程序。
arm可 ...
largewc 发表于 2013-10-31 12:25
应该不是,simd的话fp应该有8组了。
估计整数确实叠到了4组
acqwer 发表于 2013-10-31 12:52
不知和只有1L 1S的Nehalem或者Core2相比,哪个更瓶颈呢?
ifu 发表于 2013-10-31 13:50
这不能简单直接比,还涉及到TLB size和cache size之类
acqwer 发表于 2013-10-31 14:01
和双核的Nahelem比Cache也是A7大,TLB size A7没数据,你是不是要脑补个很低的数字出来啊。
最核心的问 ...
acqwer 发表于 2013-10-31 14:01
和双核的Nahelem比Cache也是A7大,TLB size A7没数据,你是不是要脑补个很低的数字出来啊。
最核心的问 ...
ifu 发表于 2013-10-31 14:21
还没发生的事你就别急吼吼的脑补扣帽子了。
苹果的开发人员是有所取舍的,无序随机访问在他们关注的领域 ...
目前看来A7在平板电脑和手机所关注的浏览器性能上相比A6提升了一倍性能,从这个意义上说A7是成功的。
largewc 发表于 2013-10-31 11:07
haswell确实也只有两个,但是haswell支持avx,加入向量矩阵的专项指令显然可以大幅度加速3d程序。
arm可 ...
acqwer 发表于 2013-10-31 14:27
别转进嘛,给出个合理的解释来。
说无序随机访问的作用,基本上所有的系统都是无序随机,能做到循序内 ...
acqwer 发表于 2013-10-31 14:31
平板电脑关注的是浏览器性能?都测试这个是因为平板手机上面压根就没几个靠谱的测试好吧,3dmark、GFX和G ...
ifu 发表于 2013-10-31 18:01
通过futuremark工作人员的描述和实验仅能将瓶颈定位为无序访存,要进一步精确定位就需要用performance mo ...
shadowlich 发表于 2013-10-31 13:37
这图只说明了ESRAM是挂在GMC上的,为何CPU不能访问?是否因为DRAM是挂在NB上的,所以GPU也不能访问呢?
largewc 发表于 2013-10-31 18:07
我认为不是缓存问题,最大的问题还是a7的浮点仍然是两个的缘故
不过a7比我想象的出色,上网a7确实理想 ...
ifu 发表于 2013-10-31 18:20
futuremark的人把数据layout优化后性能提升了2倍,要是浮点资源不足的话layout优化也是白搭
希望明年Int ...
largewc 发表于 2013-10-31 18:22
另外一个帖子我已经贴了t神说的那个函数,还是那个问题,不连续化的只有碰撞检测的物体,如果把碰撞体连续 ...
ifu 发表于 2013-10-31 18:43
采不采用simd指令在程序执行之前已经决定了的。
除非futuremark的测试中针对layout写了有simd的和没simd ...
ifu 发表于 2013-10-31 18:43
采不采用simd指令在程序执行之前已经决定了的。
除非futuremark的测试中针对layout写了有simd的和没simd ...
largewc 发表于 2013-10-31 19:06
futuremark说了已经编译器已经simd化了,后来为了测试,又手工simd化也不影响性能,说明默认编译的simd性 ...
Tempestglen 发表于 2013-10-31 20:19
你的英语令人着急啊。
futuremark的意思是,编译器确实开启了SIMD(neon),但是,没有效果,之后手动 ...
Tempestglen 发表于 2013-10-31 20:19
你的英语令人着急啊。
futuremark的意思是,编译器确实开启了SIMD(neon),但是,没有效果,之后手动 ...
Tempestglen 发表于 2013-10-31 20:37
编译器开了SIMD,没有效果,意思就是和没开SIMD一样,根本没有矢量化。
所以,哪里来的默认的SIMD性能 ...
Tempestglen 发表于 2013-10-31 20:37
编译器开了SIMD,没有效果,意思就是和没开SIMD一样,根本没有矢量化。
所以,哪里来的默认的SIMD性能 ...
Tempestglen 发表于 2013-10-31 20:54
那么futuremark那人的意思,是指对5S进行了simd编译,没有相对于iphone5的更好效果?这就讲得通了。
你 ...
Tempestglen 发表于 2013-10-31 20:56
没办法连续不要紧,连有规律的访存都做不到?有规律而不连续,prefetch一样起作用。
Tempestglen 发表于 2013-10-31 21:01
也就是说3dmark physics这种复杂程度的场景所需要的working set,对于双核A7的1M L2来说太大了?所以随机 ...
Tempestglen 发表于 2013-10-31 21:12
http://ark.intel.com/products/71459/Intel-Core-i7-3630QM-Processor-6M-Cache-up-to-3_40-GHz
3630qm ...
largewc 发表于 2013-10-31 20:49
我刚编译过PSolve_Links,可以肯定,100%进行simd编译了,无论是xcode还是vs 2012下,而且这个函数属于 ...
这样才知道哪个数据规模是拐点以及消除了访存屏障后和haswell的差距究竟有多大。Tempestglen 发表于 2013-10-31 21:12
http://ark.intel.com/products/71459/Intel-Core-i7-3630QM-Processor-6M-Cache-up-to-3_40-GHz
3630qm ...
ifu 发表于 2013-10-31 21:22
最好有个iphone5s跟iphone5以及haswell做对比
ifu 发表于 2013-10-31 21:22
最好有个iphone5s跟iphone5以及haswell做对比[lol>这样才知道哪个数据规模是拐点以及消除了访存屏障后和h ...
Tempestglen 发表于 2013-10-31 21:32
3630qm的L2到底多大呢?
Tempestglen 发表于 2013-10-31 21:32
3630qm的L2到底多大呢?
Tempestglen 发表于 2013-10-31 21:31
如果3dmark physics(ice storm)的working set大于2M比如是3M,那么S所有sox都卡在IO瓶颈上, S800/5420 ...
largewc 发表于 2013-10-31 21:00
没办法,还是这个问题,碰到的东西是随机的,这玩意肯定是new出来的,而不是一个整体内存。
ifu 发表于 2013-10-31 21:42
自己写mempool预分配优化?
ifu 发表于 2013-10-31 21:42
自己写mempool预分配优化?
Tempestglen 发表于 2013-10-31 21:07
就是说如果working set小到 L2可以容纳的地步,什么连续不连续有无规律都已经不重要了?你需要测试一下2M, ...
largewc 发表于 2013-10-31 21:58
放弃了,太麻烦,暂时我们用不到以后再说吧
ifu 发表于 2013-10-31 21:39
S800/5420/bt/A7其实也没在随机访存上占优,不过S800/5420/bt的高主频和更多的核掩盖了这一切。
你把S80 ...
ifu 发表于 2013-10-31 22:07
是比较麻烦,在程序行为以及数据规模有预期的情况下对核心数据用自己的mempool还是可以收到不错的效果。
...
largewc 发表于 2013-10-31 22:11
mempool我们有的,只是对小额内存和相对尺寸固定的有用
物理的数组都是不确定长度的,引用的对象更是 ...
ifu 发表于 2013-10-31 22:32
实在无法连续分配内存的情况下,可以通过手工prefetch优化。像我前面提的二叉树查找,如果bullet有的话就 ...
westlee 发表于 2013-10-31 22:34
不同缓存数量的c2d在新3dmark中的成绩。
具体的缓存数量就不用科普了吧。
Tempestglen 发表于 2013-10-31 22:53
1)futuremark的人说psolve link消耗了几乎所有的cpu时间。
2)我刚才举了cortex A15和cyclone的例子。 ...
largewc 发表于 2013-10-31 22:36
怎么优化二叉树查找?我很好奇,要知道,这个树是自衡二叉树,不停得在增减东西的。
largewc 发表于 2013-10-31 22:46
估计是a7缓存设计有问题,我的3630因此带来的影响是缓慢提升的,而且即使到超过了20m影响也超不过50%。 ...
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
