原帖由 downdown 于 2008-6-25 12:48 发表
[打][酱油]居然也被屏蔽。。:funk: :funk:
原帖由 downdown 于 2008-6-25 12:48 发表
[打][酱油]居然也被屏蔽。。:funk: :funk:
 英特尔CEO欧德宁近日表示,英特尔并未像微软垄断桌面市场那样垄断计算机处理器市场。
英特尔CEO欧德宁近日表示,英特尔并未像微软垄断桌面市场那样垄断计算机处理器市场。原帖由 Ricepig 于 2008-6-26 03:56 发表
其实还是比较像~~~除了内存控制器,还有有别于fsb的总线,和三级缓存
也许是到了多核以后,为了可扩展,必然这么搞~~~
| Model | Speed (GHz) | L3 Cache (MB) | FSB (MHz) | TDP (Watts) |
| 7110N | 2.50 | 4 | 667 | 95 |
| 7110M | 2.60 | 4 | 800 | 95 |
| 7120N | 3.00 | 4 | 667 | 95 |
| 7120M | 3.00 | 4 | 800 | 95 |
| 7130N | 3.16 | 8 | 667 | 150 |
| 7130M | 3.20 | 8 | 800 | 150 |
| 7140N | 3.33 | 16 | 667 | 150 |
| 7140M | 3.40 | 16 | 800 | 150 |
原帖由 elisha 于 2008-6-25 14:22 发表
AMD继续领先6年
原帖由 feixiong 于 2008-6-26 11:12 发表
来不及思考在OCP也发表了类似说法,飞龙的结构设计还是很不错的,要不然Nehalem也不会采用相似的设计,问题出现在AMD糟糕的生产工艺上!!!
以下为引用其发言:
这个新闻纯粹是放P
等着看上海吧
上海的性 ...
原帖由 feixiong 于 2008-6-26 11:12 发表
来不及思考在OCP也发表了类似说法,飞龙的结构设计还是很不错的,要不然Nehalem也不会采用相似的设计,问题出现在AMD糟糕的生产工艺上!!!
以下为引用其发言:
这个新闻纯粹是放P
等着看上海吧
上海的性 ...
原帖由 AMD11 于 2008-6-26 13:13 发表
还有:“K10在SPEC CINT2000中的几个项目,与core2差距超过500%。vpr、mfc都是最容易出现cache容量miss的地方,K10目前几乎就彻底栽在这个地方上”
(1)能否给出连接?
(2)能否说说mfc在哪处“最容易出现ca ...
原帖由 feixiong 于 2008-6-26 14:34 发表
LS的LS,我菜鸟一个,可没有水平说出这种话,以上为引用来不及思考在ITOCP的发言而已!
http://www.itocp.com/viewthread.php?tid=5352&highlight=K10
http://www.itocp.com/viewthread.php?tid=4506&highligh ...
原帖由 feixiong 于 2008-6-26 14:52 发表
LS的老兄你就直说吧非龙靠增大L3能不能大幅提高性能?
原帖由 acqwer 于 2008-6-26 15:02 发表
K10.5如果就是增加L3、拉点频率这点改进的话,估计最多也就是intel的65到45的提升了(不计SSE4)。
原帖由 feixiong 于 2008-6-26 14:34 发表
LS的LS,我菜鸟一个,可没有水平说出这种话,以上为引用来不及思考在ITOCP的发言而已!
http://www.itocp.com/viewthread.php?tid=5352&highlight=K10
http://www.itocp.com/viewthread.php?tid=4506&highligh ...
原帖由 feixiong 于 2008-6-26 14:34 发表
LS的LS,我菜鸟一个,可没有水平说出这种话,以上为引用来不及思考在ITOCP的发言而已!
http://www.itocp.com/viewthread.php?tid=5352&highlight=K10
http://www.itocp.com/viewthread.php?tid=4506&highligh ...
原帖由 downdown 于 2008-6-25 12:48 发表
[打][酱油]居然也被屏蔽。。:funk: :funk:
原帖由 acqwer 于 2008-6-26 15:02 发表
K10.5如果就是增加L3、拉点频率这点改进的话,估计最多也就是intel的65到45的提升了(不计SSE4)。
原帖由 OCFish 于 2008-6-26 17:10 发表
这两公司在CPU设计能力上的差距远没有制程来得大,否则A也活不到今天.批判一事物的时候切误搞全盘否定.A要靠K10这个构架搞至少2~3年,既然他们的工程师用这种设计他们的高层批准这种方案他们的股东认可这种路线.自然有它的可取之处,除非你觉得这些个人都不如你.
K10现在的局面主要是BUG和制程造成的,楼上的那个分析很客观我不知道有什么可喷的.抱开宣传手段和无脑枪文Nehalem从现阶段透露的资料来看确实不比K10高明多少.那么就从手头现有的东西来看鼓吹未来的Nehalem就等于鼓吹未来的K10或者K10.5。唯一的区别是Nehalem还没出演而K10已经演黄了需要重新排练。自K6以后两家产品基本客观的反映了各方面的客观差距。当然只有FANS才更关注哪家失误了哪家超水平发挥了,不过这一出戏缺了这些因素就没有戏剧性了。
另外处理器发展都是循序渐进的,Core这种构架体现出来的革命性更多的来源于Netburst的失误和K8的不思进取.从结果来反推原因总是相对简单的过程.
原帖由 OCFish 于 2008-6-26 17:10 发表
K10现在的局面主要是BUG和制程造成的
原帖由 AMD11 于 2008-6-26 16:42 发表
可惜我没有ittop的账号,否则真应该问问“来不及思考”为什么说“vpr、mfc都是最容易出现cache容量miss的地方”这句话,如何得出这个结论。:funk:
原帖由 OCFish 于 2008-6-26 17:10 发表
这两公司在CPU设计能力上的差距远没有制程来得大,否则A也活不到今天.批判一事物的时候切误搞全盘否定.A要靠K10这个构架搞至少2~3年,既然他们的工程师用这种设计他们的高层批准这种方案他们的股东认可这种路线.自然有它的可取之处,除非你觉得这些个人都不如你.
K10现在的局面主要是BUG和制程造成的,楼上的那个分析很客观我不知道有什么可喷的.抱开宣传手段和无脑枪文Nehalem从现阶段透露的资料来看确实不比K10高明多少.那么就从手头现有的东西来看鼓吹未来的Nehalem就等于鼓吹未来的K10或者K10.5。唯一的区别是Nehalem还没出演而K10已经演黄了需要重新排练。自K6以后两家产品基本客观的反映了各方面的客观差距。当然只有FANS才更关注哪家失误了哪家超水平发挥了,不过这一出戏缺了这些因素就没有戏剧性了。
另外处理器发展都是循序渐进的,Core这种构架体现出来的革命性更多的来源于Netburst的失误和K8的不思进取.从结果来反推原因总是相对简单的过程. ...
原帖由 AMD11 于 2008-6-26 16:36 发表
我单独从你给出的连接中“http://www.itocp.com/viewthread.php?tid=5352&highlight=K10”截出图的一部分,可是我还是不明白,为什么在会差距这么大,虽然是K8与Core 2的对比,而不是K10的,难道mfc的测试中,对 ...
原帖由 soft 于 2008-6-26 19:40 发表
CINEBENCH R10
这个测试结果怎么样?我没啥概念
原帖由 soft 于 2008-6-26 19:40 发表
这个测试结果怎么样?我没啥概念

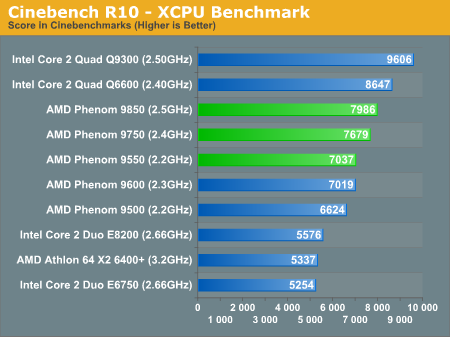
原帖由 naze 于 2008-6-26 20:19 发表
Q9650@3G Vs Nehalem ES@2.93G
11839 Vs 14299
同频提高20%
参考 anandtech测试 hehalem2.5G应该是9606*(1+20%)=11527.2
对比同频的phenom 9850 (11527.2-7986)/7986=44%
amd拿什么来拼命 Nehalem可是第四 ...
原帖由 OCFish 于 2008-6-26 17:10 发表
这两公司在CPU设计能力上的差距远没有制程来得大,否则A也活不到今天.批判一事物的时候切误搞全盘否定.A要靠K10这个构架搞至少2~3年,既然他们的工程师用这种设计他们的高层批准这种方案他们的股东认可这 ...
原帖由 OCFish 于 2008-6-26 17:10 发表
这两公司在CPU设计能力上的差距远没有制程来得大,否则A也活不到今天.批判一事物的时候切误搞全盘否定.A要靠K10这个构架搞至少2~3年,既然他们的工程师用这种设计他们的高层批准这种方案他们的股东认可这 ...
原帖由 feixiong 于 2008-6-26 11:12 发表
来不及思考在OCP也发表了类似说法,飞龙的结构设计还是很不错的,要不然Nehalem也不会采用相似的设计,问题出现在AMD糟糕的生产工艺上!!!
以下为引用其发言:
这个新闻纯粹是放P
等着看上海吧
上海的性 ...
原帖由 boybrood 于 2008-6-26 20:37 发表
等着吧,又是一个过度品
原帖由 frankincense 于 2008-6-26 20:33 发表
单核心效率倒是只和Core2持平
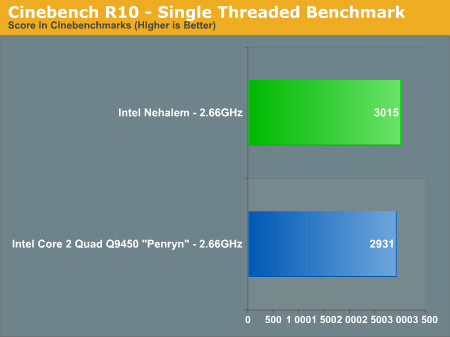
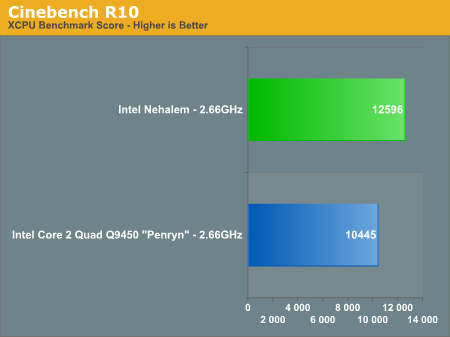
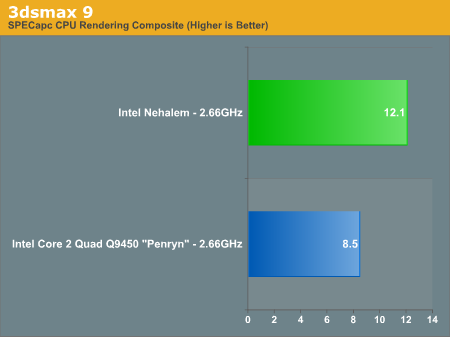
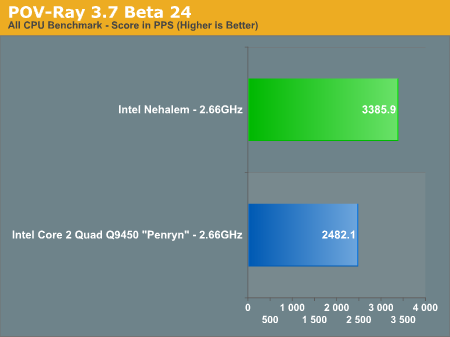
原帖由 frankincense 于 2008-6-26 20:33 发表
单核心效率倒是只和Core2持平
| 欢迎光临 POPPUR爱换 (https://we.poppur.com/) | Powered by Discuz! X3.4 |
