|
|
本帖最后由 Hyins 于 2010-2-3 18:54 编辑
官方详细介绍:
http://www.nvidia.cn/object/gf100_cn.html
GF100白皮书:
http://www.nvidia.cn/object/IO_86775.html
http://www.nvidia.cn/object/IO_86776.html
不违规搭车宣传下:NVIDIA FANS高级群79567440
根据目前透露出来的信息 应该是再一次完胜AMD
http://we.pcinlife.com/thread-1312773-1-1.html
以下文章转自驱动之家的上方文Q:
2009年十一期间,NVIDIA第一次向我们展示了代号Fermi的全新图形架构,不过几乎完全是关于通用计算的,展示了NVIDIA开辟新领域的决心。到了今年初的CES 2010上,NVIDIA终于首次公开拿出了Fermi架构高端型号GF100,展示立体多屏环绕技术3D Vision Surround的同时,内部运行了几个新的演示DEMO。
今天,NVIDIA终于公开了Fermi GF100在游戏的架够方面的诸多特性,这才是普通消费者最为关心的,也是我们要和大家分享的。
![]()
不过我们仍未看到最终零售版的GF100显卡,不少关键的核心参数也暂时缺失,所以如果你急切地想知道下边这些内容,抱歉要失望了。
Fermi芯片至今仍未开始真正的批量生产,而核心面积在很大程度上决定着良品率,良品率又是时钟频率的前提,功耗和性能又都是建立在频率基础上,它们又都是价格的组成要素。当然了,GF100必须要比Radeon HD 5870速度更快,而且领先幅度要尽量高;功耗和价格也已经不可避免地要更高,只看能控制到什么程度了。
下边是2009年9月1日拍摄的Fermi GF100内核照片: ![]()
一、GF100游戏架构的两颗新心脏
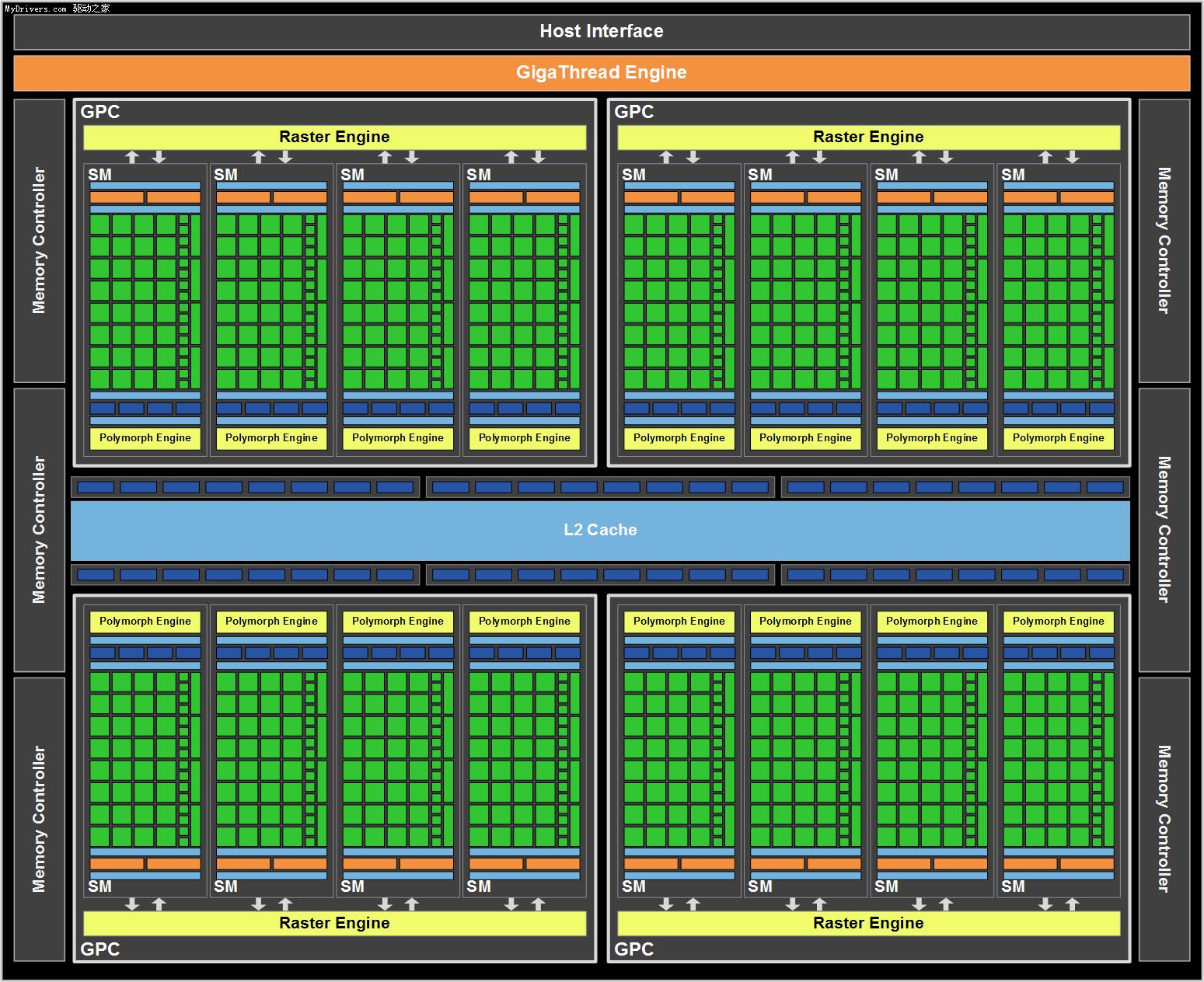
我们已经知道,GF100采用台积电40nm工艺制造,集成大约30亿个晶体管,包含512个流处理器(SP),或者按照NVIDIA官方的说法是CUDA核心。32个这种核心组成一个流式多处理器阵列(SM),然后再四个组成一个图形处理集群(GPC)。GF100就是这样的三层分级架构:4个GPC、16个SM、512个SP。
此外GF100还有64个纹理寻址单元、256个纹理过滤单元、48个ROP单元,显存位宽384-bit,搭配GDDR5颗粒。核心/Shader/显存频率都没有定夺,显存容量也尚待确定。 | GF100 | GTX 295 | GTX 285 | 9800 GTX+ | | 流处理器 | 512 | 2 x 240 | 240 | 128 | | 纹理寻址/过滤单元 | 64/256 | 2 x 80 / 80 | 80 / 80 | 64 / 64 | | ROP单元 | 48 | 2x 28 | 32 | 16 | | 核心频率 | ? | 576MHz | 648MHz | 738MHz | | Shader频率 | ? | 1242MHz | 1476MHz | 1836MHz | | 显存频率 | ? GDDR5 | 999MHz GDDR3 | 1242MHz GDDR3 | 1100MHz GDDR3 | | 显存带宽 | 384-bit | 2 x 448-bit | 512-bit | 256-bit | | 显存容量 | ? | 2 x 896MB | 1GB | 512MB | | 晶体管 | 3B | 2 x 1.4B | 1.4B | 754M | | 制造工艺 | TSMC 40nm | TSMC 55nm | TSMC 55nm | TSMC 55nm | | 价格 | $? | $500 | $400 | $150 - 200 |
先看一下NVIDIA最新公布的比较详尽的GF100架构图,接下来我们就详细阐述其中的几个重点之处。 ![]()
NVIDIA声称Fermi GF100是一个全新架构并非没有道理。不但是通用计算方面,游戏方面它也发生了翻天覆地的变化,几乎每一个原有模块都进行了重组:有的砍掉了,有的转移了,有的增强了,还有新增的光栅引擎(Raster Engine)和多形体引擎(PolyMorph Engine)。 ![]()
光栅引擎严格来说光栅引擎并非全新硬件,只是此前所有光栅化处理硬件单元的组合,以流水线的方式执行边缘/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴压缩(Z-Culling)等操作,每个时钟循环周期处理8个像素。GF100有四个光栅引擎,每组GPC分配一个,整个核心每周期可处理32个像素。 ![]()
多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里。GF100中有16个多形体引擎,每组SM一个,亦即每组GPC四个。 ![]()
多形体引擎绝非几何单元改头换面、增强15倍而已,它融合了之前的固定功能硬件单元,使之成为一个有机整体。虽然每一个多形体引擎都是简单的顺序设计,但16个作为一体就能像CPU那样进行乱序执行(OoO)了,也就是趋向于并行处理。NVIDIA还特地为这些多形体引擎设置了一个专用通信通道,让它们在任务处理中维持整体性。
当然,这种变化复杂得要命,也消耗了NVIDIA工程师无数的精力、资源和时间。事实上可以这么说,多形体引擎正是GF100核心最大的变化所在,也是它无法在去年及时发布的最大原因。NVIDIA产品营销副总裁Ujesh Desai说过这么一句话:设计这么大的GPU实在是太TMD难了。其实,他指的并不是30亿个晶体管。
这么做也是不得已而为之。考虑到细分曲面单元的几何复杂性,固定功能流水线已经不适用,整个流水线都需要重新平衡。通过多形体引擎的并行设计,几何硬件不再受任何固定单元流水线的局限,可以根据芯片尺寸弹性伸缩。和之前的GT200/G92以及AMD相比,GF100走上了另一条路,而且颇有要做CPU的架势。 ![]()
在每一组SM阵列里,纹理单元、一二级缓存、ROP单元和各个单元的频率也都完全不同于以往。每组SM里四个纹理单元,合伙使用12KB一级纹理缓存,并和整个芯片共享768KB二级缓存。每个纹理单元每周期可计算一个纹理寻址、拾取四个纹理采样,并支持DX11新的压缩纹理格式。
ROP单元总共48个,分为六组,分别搭配一个64-bit显存通道。所有ROP单元和整个芯片共享768KB二级缓存(GT200里是独享)。
除了ROP单元和二级缓存,几乎其他所有单元的频率都和Shader频率(NVIDIA暂称之为GPC频率)关联在一起:一级缓存和Sahder单元本身是全速,纹理单元、光栅引擎、多形体引擎则都是一半。对于GF100来说,想超频的话很多地方都要重新来过了。 ![]()
二、NVIDIA为何如此关注几何性能
在微软DX11规范的严格限制下,留给NVIDIA(还有AMD)自由发挥的空间并不大:不遵从当然不行,完全照搬就缺乏特色,自行其事又可能只是无用功。最终,NVIDIA选择了在速度上做文章。
从NV30 GeForce FX 5800到GT200 GeForce GTX 280,NVIDIA显卡的几何性能只提高了不到3倍,而Shader性能提升了150多倍,但仅仅是从GT200到GF100,几何性能的增长倍数就达到了8x。
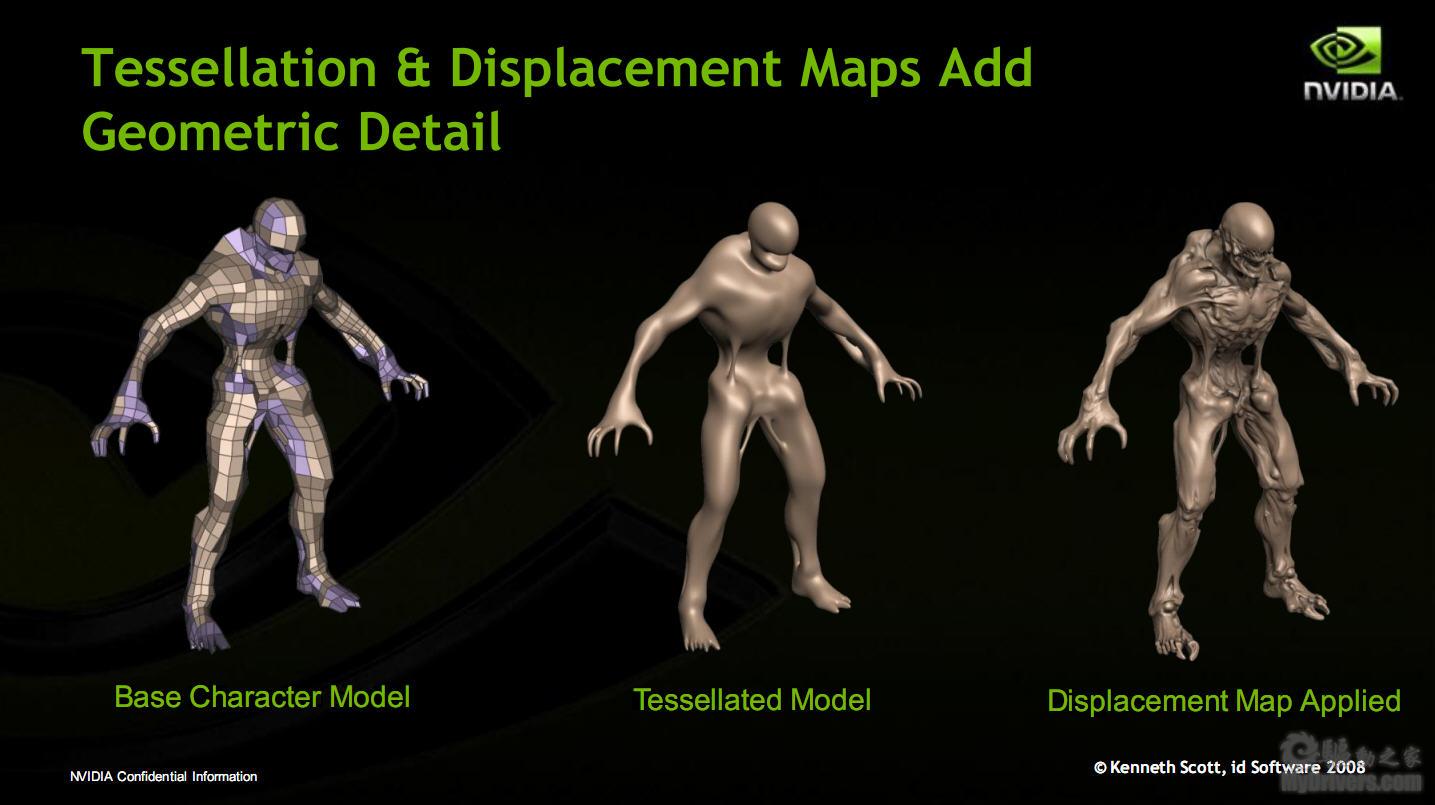
有了如此强大的几何性能,NVIDIA就可以使用细分曲面和置换贴图创建更复杂的人物、物体和场景,并保持和对手同样水平的性能,所以才有了16个多形体引擎和4个光栅引擎。
细分曲面是AMD DX11产品的宣传重点,但NVIDIA要做得复杂得多,而且理论上说效果更出色。接下来NVIDIA要做的就是让游戏开发商充分挖掘GF100架构的潜力,在保证性能的基础上做出更精致的游戏画面。 ![]()
![]()
![]()
细分曲面渲染过程示意图
![]()
NVIDIA水面细分曲面DEMO
![]()
NVIDIA头发细分曲面DEMO
三、更好的画质:
1、抖动采样(Jittered Sampling)
DX11详细定义了显卡需要提供的特性,但对渲染后端的工作涉及甚少,所以NVIDIA做了多形体引擎,还有抖动采样。
抖动采样不是新技术,长期用于阴影贴图和各种后期处理,通过对临近纹素(Texel/纹理上的像素点)进行采样来创建更柔和的阴影边缘。它的缺点也是非常消耗资源。
DX9/10上抖动采样是分别拾取每一个纹素,DX10.1开始改用Gather4指令,NVIDIA则在硬件上使用单独一条矢量指令。NVIDIA自己的测试显示,这么做的性能大约是非矢量执行的两倍。
对游戏开发商来说,这意味着消耗的硬件资源更少;对游戏玩家来说,则意味着更好的画质。 ![]()
![]()
2、抗锯齿加速
和AMD一样,NVIDIA也对ROP单元做出了调整,以减少在MSAA(多重采样抗锯齿)下的性能损失,还有更多ROP单元来改善性能。
根据NVIDIA提供的数据,在《鹰击长空》里,8x/4x MSAA模式下GF100的性能分别是GeForce GTX 285的2.33倍和1.61倍。 ![]()
|
|



 [复制链接]
[复制链接]


 IP卡
IP卡 狗仔卡
狗仔卡
 发表于 2010-1-18 19:08
发表于 2010-1-18 19:08




 QQ好友和群
QQ好友和群 收藏
收藏 分享
分享 好贴
好贴 烂贴
烂贴 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡
 说的天花乱坠 就是没有实卡
说的天花乱坠 就是没有实卡


 楼主
楼主