http://blog.icare3d.org/2010/06/ ... le-pass-buffer.html
One of the first thing I wanted do try on the GF100 was the new NVIDIA extensions that allows random access read/write and atomic operations into global memory and textures, to implement a fast A-Buffer !
It worked pretty well since it provides something like a 1.5x speedup over the fastest previous approach (at least I know about !), with zero artifact and supporting arbitrary number of layers with a single geometry pass.
![]() ![]()
Sample application sources and Win32 executable:
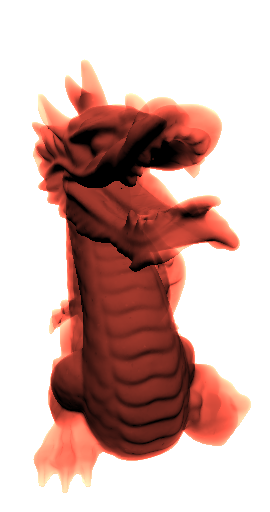
Sources+executable+Stanford Dragon model
Additional models
Be aware that this will probably only run on a Fermi card. In particular it requires:EXT_shader_image_load_store, NV_shader_buffer_load, NV_shader_buffer_store,EXT_direct_state_access
Application uses freeglut in order to initialize an OpenGL 4.0 context with the core profile.
A-Buffer:
Basically an A-buffer is a simple list of fragments per pixel [Carpenter 1984]. Previous methods to implement it on DX10 generation hardware required multiple passes to capture an interesting number of fragments per pixel. They where essentially based on depth-peeling, with enhancements allowing to capture more than one layer per geometric pass, like the k-buffer and stencil routed k-buffer that suffers from read-modify-write hazards.Bucket sort depth peeling allows to capture up to 32 fragments per geometry pass but with only 32 bits per fragment (just a depth) and at the cost of potential collisions.
All these techniques were complex and basically limited by the maximum of 8 render targets that were writable by the fragment shader.
My technique can handle arbitrary number of fragments per pixels in a single pass, with only limitation the available video memory. In this example, I do order independent transparency with fragments storing 4x32bits values containing RGB color components and the depth.
Technique:
The idea is very simple: Each fragment is written by the fragment shader at it's position into a pre-allocated 2D texture array (or a global memory region) with a fixed maximum number of layers. The layer to write the fragment into is given by a counter stored per pixel into another 2D texture and incremented using an atomic increment (or addition) operation ( [image]AtomicIncWrap or [image]AtomicAdd). After the rendering pass, the A-Buffer contains an unordered list of fragments per pixel with it's size. To sort these fragments per depth and compose them on the screen, I simply use a single screen filling quad with a fragment shader. This shader copy all the pixel fragments in a local array (probably stored in L1 on Fermi), sort them with a naive bubble sort, and then combine them front-to-back based on transparency.
Performances:
To compare performances, this sample also features a standard rasterization mode which renders directly into the color buffer. On the Stanford Dragon example, a GTX480 and 32 layers in the A-Buffer, the technique range between 400-500 FPS, and is only 5-20% more costly than a simple rasterization of the mesh.
I also compared performances with the k-buffer which code is available online. On the GTX480, with the same model and shading (and 16 layers), I can get more than a 2x speedup, without the artifacts of the k-buffer version. Based on that results, I strongly believe that it is also close to 1.5x faster than the bucket sort depth peeling, without it's depth collision problems.
Artifacts comparison with the K-Buffer:
OpenGL 4.0 K-Buffer | 




 IP卡
IP卡 狗仔卡
狗仔卡
 发表于 2010-6-10 17:47
发表于 2010-6-10 17:47







 QQ好友和群
QQ好友和群 收藏
收藏 分享
分享 好贴
好贴 烂贴
烂贴 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 楼主
楼主