|
|
|
美国加州帕洛阿尔托市举行的第22届Hot Chips高性能芯片大会上,AMD如约公布了“推土机”(Bulldozer)、“山猫”(Bobcat)两款全新处理器架构的更多技术细节。AMD院士兼推土机总设计师Mike Butler、AMD院士兼山猫总设计师Brad Burgess均出席会议并分别发表了相关演讲。 ![]()
推土机架构主攻性能和扩展性,面向主流客户端和服务器领域,山猫架构的重点则是灵活性、低功耗和小尺寸,将用于低功耗设备、小型设备、云客户端。![]()
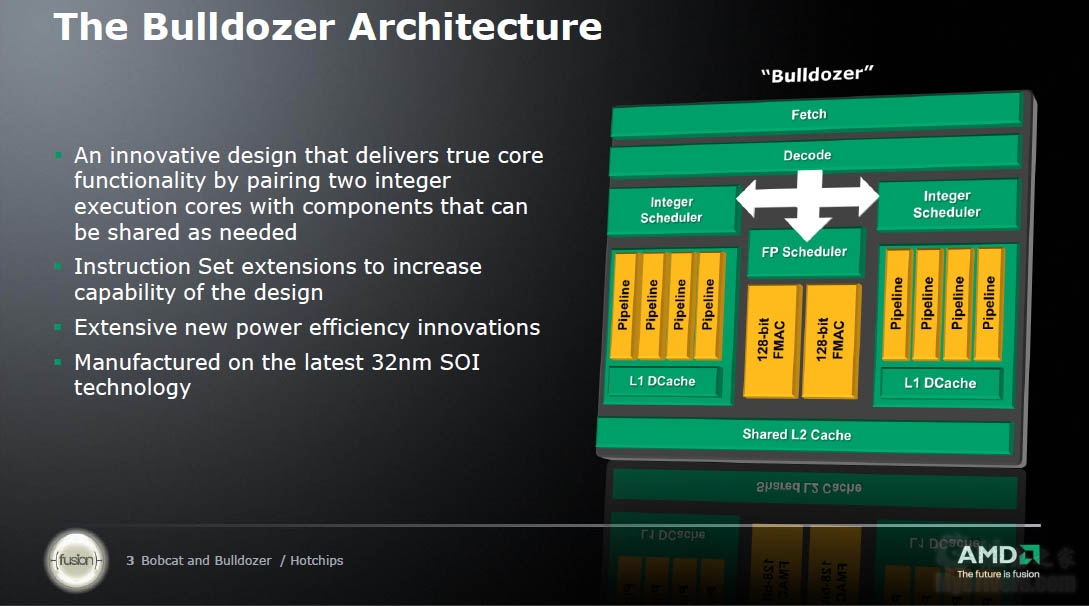
推土机将采用新的模块化设计,每个模块拥有两个四管线核心,彼此共享一个浮点调度器和两个128位乘法累加单元(FMAC)。两个核心都拥有自己的整数调度器、一级数据缓存,并预取、解码单元和二级缓存。 新架构还将有全新的x86指令集支持,包括SSE4.1、SSE4.2、AVX、XOP。![]()
![]()
推土机微架构示意图
![]()
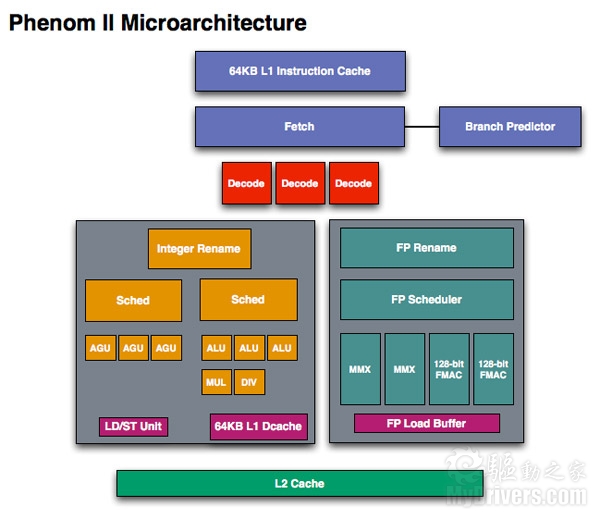
K10 Phenom II微架构示意图
因为除了高性能计算领域之外浮点运算量并不多,这种浮点调度器共享设计能大大节省晶体管、核心面积、功耗,降低成本;两个FMAC单元既可以被每个核心单独使用,也可以合并组成一个256位FMAC单元,当然这需要程序代码做相应改变。为了获得最大程度的性能功耗比,推土机架构还会在共享、专用单元之间动态切换。 ![]()
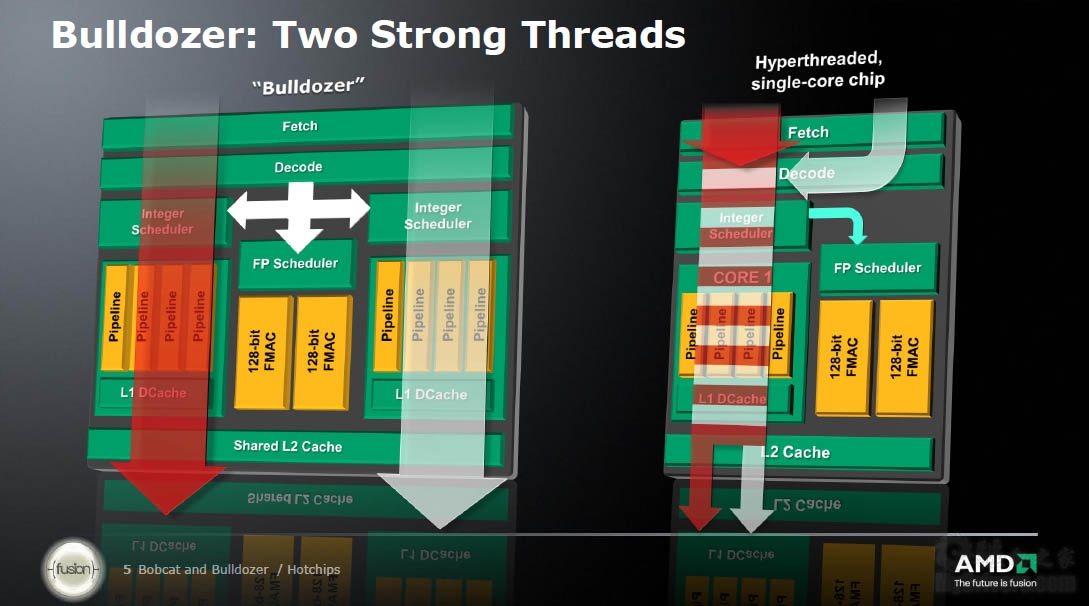
AMD宣称,这种共享模块化设计的多线程执行效率要大大优于同步多线程(SMT)和芯片多处理(CMP)。SMT最典型的实例就是Intel的超线程技术,它强制两个线程进入一个核心,线程之间会争夺资源,影响效率;CMP则是一个线程对应多个专用核心,浪费资源。 ![]()
![]()
推土机的模块可以通过HyperTransport高速点对点总线多个累加在一起,组成更多核心产品,比如代号英特拉格斯的Opteron 6200系列服务器处理器就有6-8个模块、12-16个核心,代号巴伦西亚的Opteron 4200系列则有3-4个模块、6-8个核心,它们会分别取代现有的8-12核心Opteron 6100系列、4-6核心的Opteron 4100系列,均采用GlobalFoundries 32nm SOI工艺制造。
AMD表示,模块化设计能够加速芯片开发、提高产品灵活性,同时对硬件、操作系统、应用软件来说都是透明的。 ![]()
此外推土机还是一个非常强调效能的架构,支持更先进的电源管理技术。因为浮点单元上的共享,每个模块内第二个整数核心所需要的电路只占总核心面积的12%,从芯片级别上讲这只会给整个内核增加5%的电路。更多的核心、更少的空间,这显然有利于提高单位功耗、单位成本的性能。 ![]()
简单地说,推土机是AMD彻底重新设计的核心,将成为AMD下一代高性能处理器技术,用于客户端和服务器领域,相比于Opteron 6100系列会增加33%的核心、大约50%的性能。 ![]()
再来看山猫,这是一种小尺寸、高效能、低功耗的x86核心,同时具有出色的性能,可在不同设计、制造工艺上轻松移植。 ![]()
山猫核心使用的是乱序执行引擎(Atom是顺序执行),集成两个x86解码器、高级分支预测期、完整乱序指令执行、完整乱序载入与存储引擎、高性能浮点单元、32KB一级缓存、512KB二级缓存,完整支持ISA、SSE1/2/3、SSSE3指令集和虚拟化技术,单个核心功耗可降至1W以下,估计能以不到一半的核心面积达到当今主流性能的90%。![]()
![]()
| ![]()
山猫微架构示意图![]()
Atom微架构示意图![]()
山猫架构管线![]()
Atom架构管线山猫架构的首款产品是即将于今年底明年初发布、面向轻薄本和上网本的第一款Fusion APU加速处理器“安大略湖”(Ontario),确切地说是其中的CPU部分。Ontario APU之内除了山猫CPU引擎之外,还有SIMD引擎阵列(GPU图形核心)、UVD解码单元、高性能总线和内存控制器、系统接口,将采用台积电40nm工艺制造。 ![]() ![]()
|
|
|





 IP卡
IP卡 狗仔卡
狗仔卡
 发表于 2010-8-24 18:28
发表于 2010-8-24 18:28


















 QQ好友和群
QQ好友和群 收藏
收藏 分享
分享 好贴
好贴 烂贴
烂贴 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡



