|
|
voidshatter 发表于 2011-6-14 00:49 ![]()
瞻仰一下大牛~
请教一下,如果是一个最基本的简单问题,纯算对数函数的话,比如说是一个巨大的双精度 ...
理论上说,由于现在A卡都是走暴力运算的路子,只要能够100%利用运算资源,那是肯定比同级N卡的运算性能要快的。但是,又是由于A卡的暴力运算架构(4D或者4D+1D),导致在计算过程中的优化是必须的。
我怀着恶意推测AMD的OpenCL工具是无法进行SP级别优化的,那也就是说必须由开发人员来完成底层的资源利用优化;而NV的CUDA则基本不需要开发者来做SP级别的优化。这就导致同级N卡的通用计算性能基本上都会高过A卡。
尤其是你说得巨大矩阵的运算,CUDA占得优势那是太大了,不论是从并行线程能力上还是资源调配上。具体信息你可以参考David Kirk写的这本书:
Programming Massively Parallel Processors: A Hands-on Approach |
|





 IP卡
IP卡 狗仔卡
狗仔卡
 发表于 2011-6-13 19:53
发表于 2011-6-13 19:53


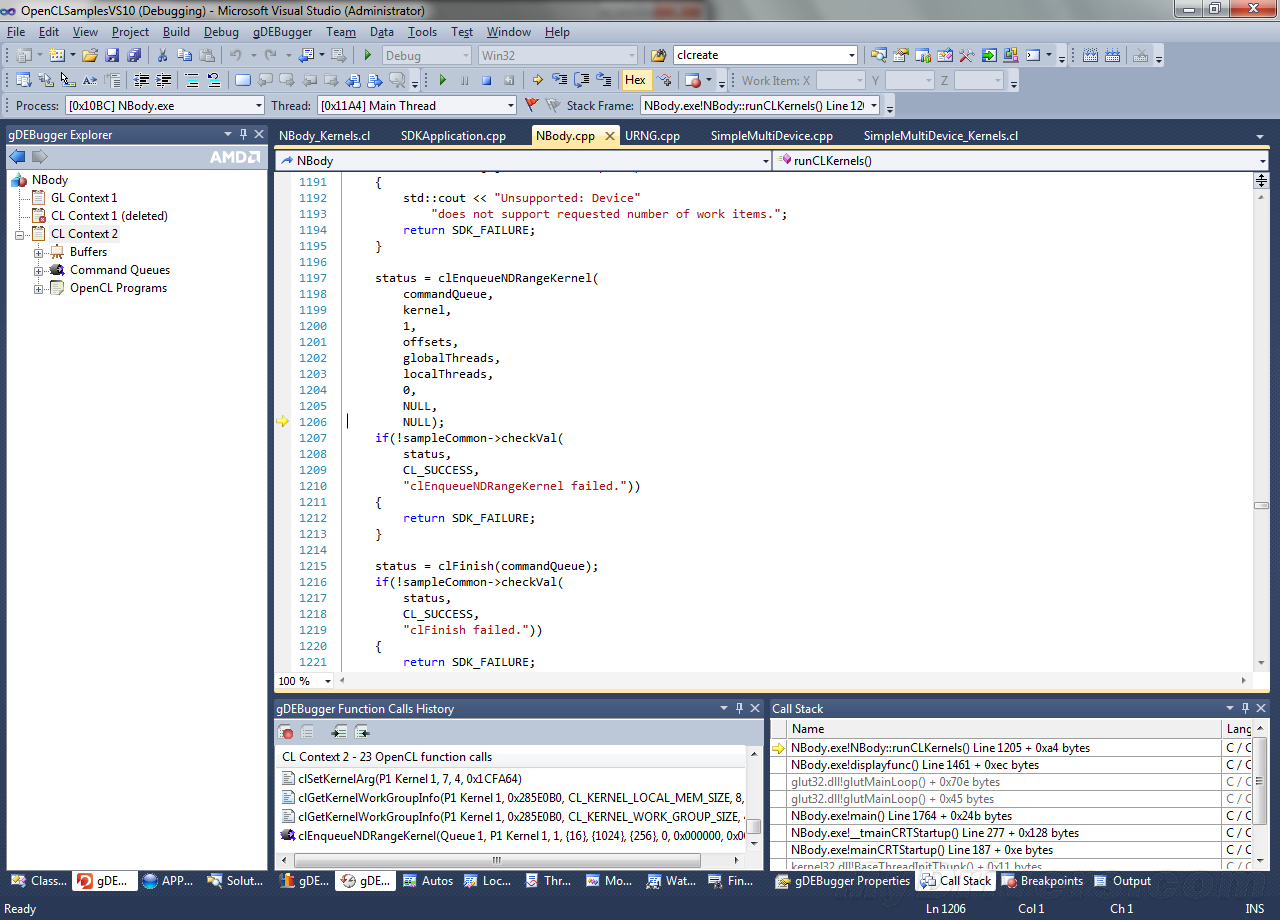
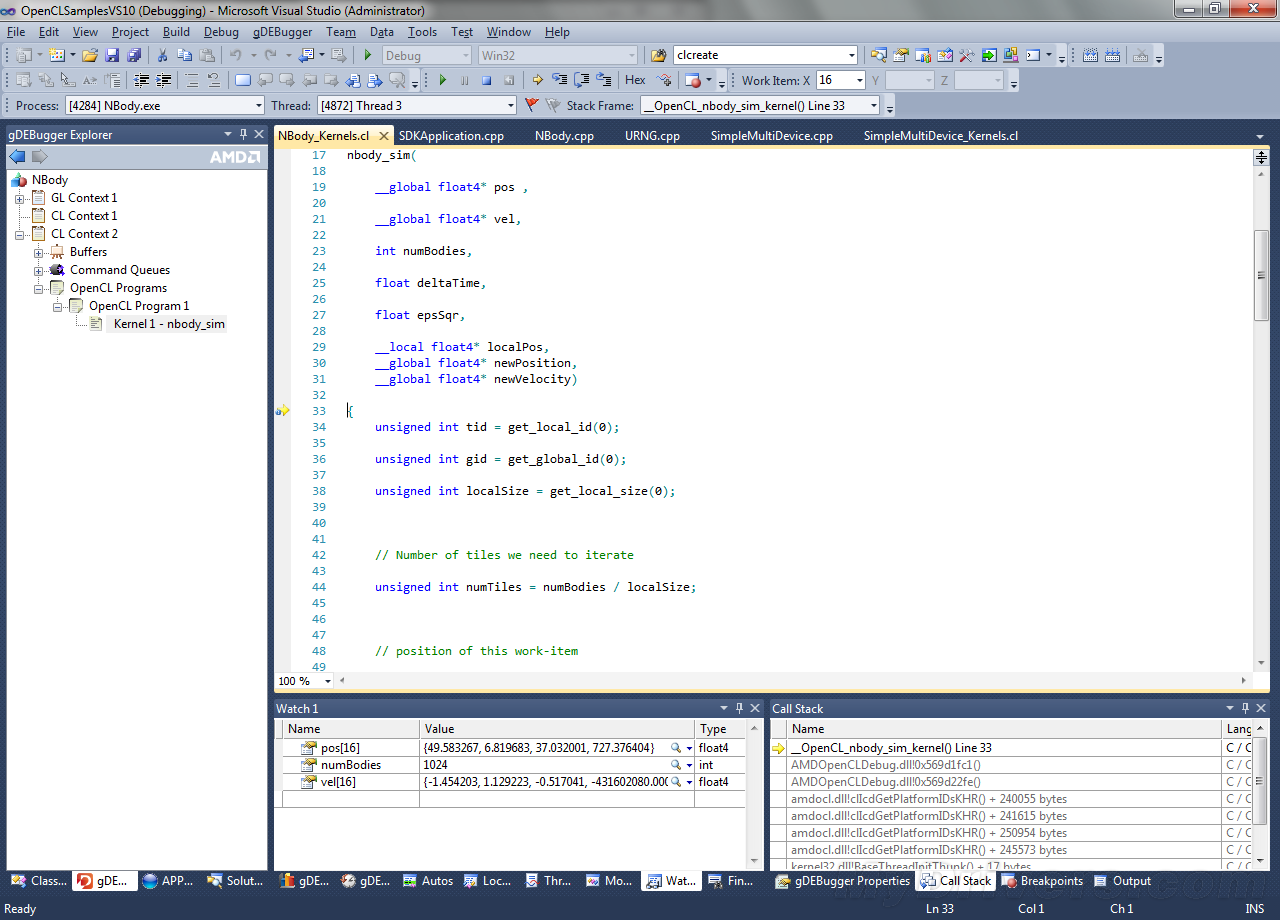
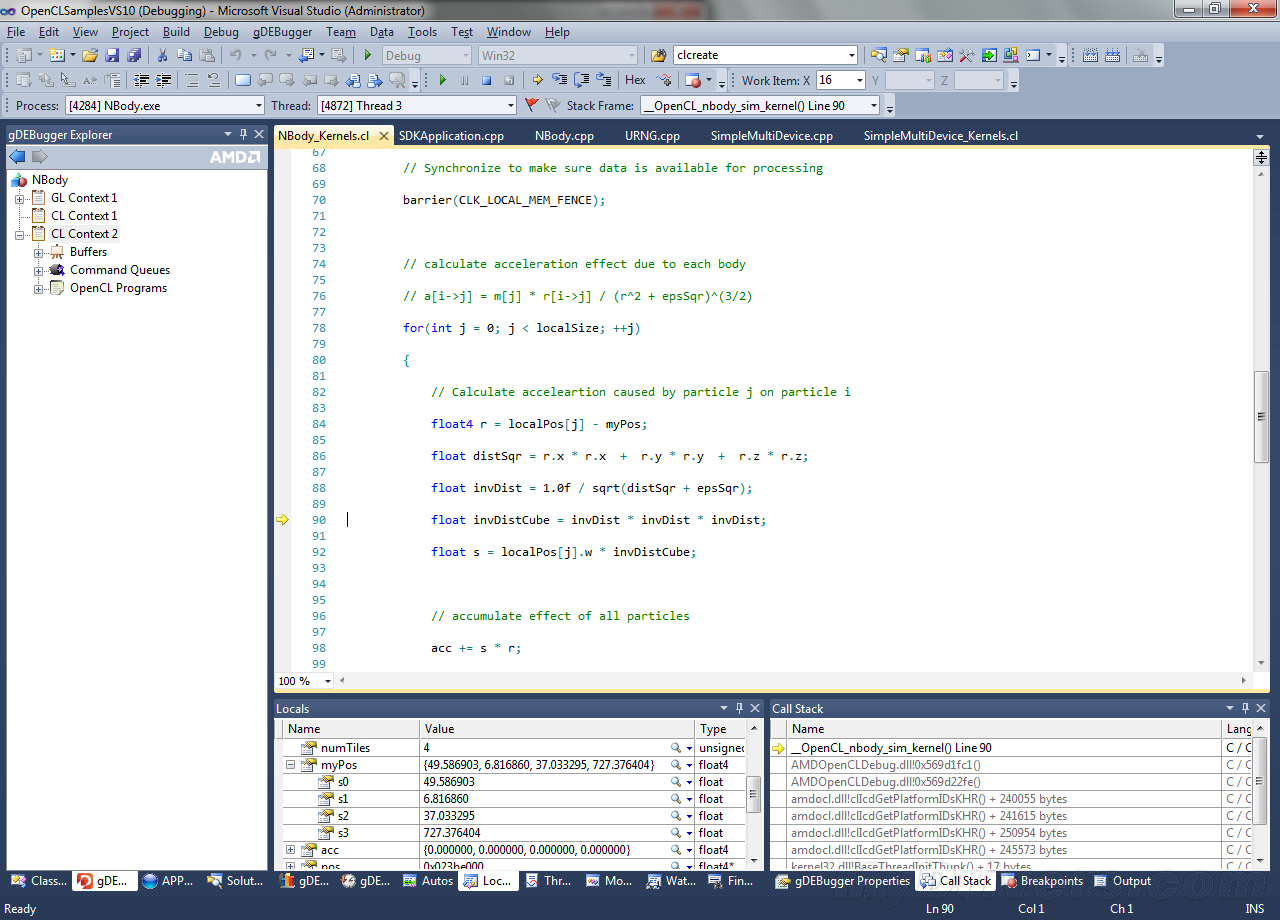
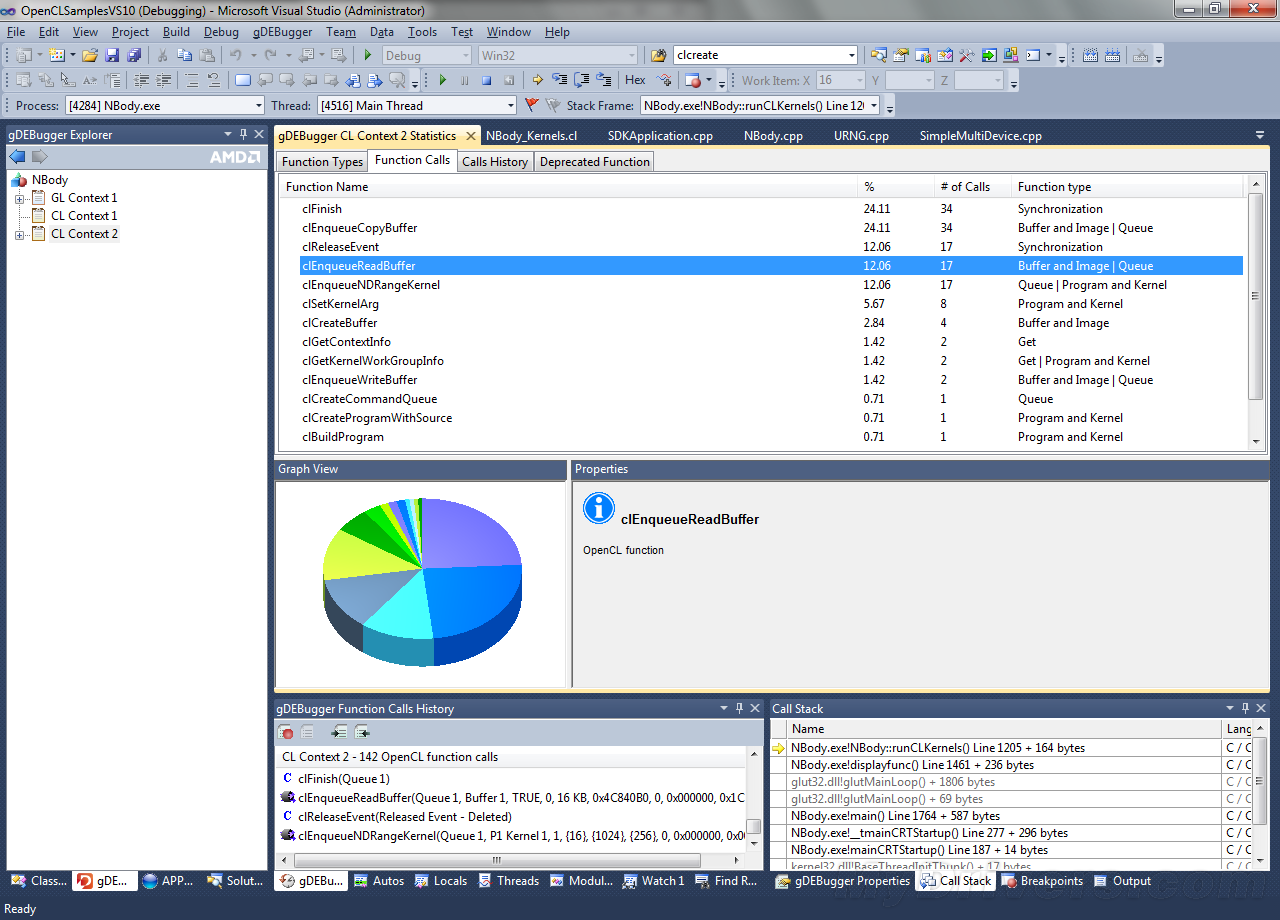
 QQ好友和群
QQ好友和群 收藏
收藏 分享
分享 好贴
好贴 烂贴
烂贴 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡